
"Engineering Insights" es una serie de artículos de blog que ofrece una perspectiva interna sobre los retos técnicos, las lecciones aprendidas y los avances que permiten a nuestros clientes proteger a las personas y defender los datos a diario. En los artículos que escriben, nuestros ingenieros explican el proceso que condujo a una innovación de Proofpoint.
Las organizaciones se enfrentan a amenazas constantes como consecuencia de actividades internas. Esto hace que sea crucial identificar cuándo los comportamientos de los usuarios se alejan de lo habitual. Otro caso de uso crítico es evitar que los datos confidenciales salgan de una organización sin ser detectados.
En Proofpoint, hemos diseñado un sofisticado sistema de detección de anomalías. No solo crea los perfiles de comportamiento individuales de los usuarios, sino que también agrega información específica de los inquilinos (tenant). Esto aumenta su precisión a la hora de detectar y prevenir amenazas para la seguridad.
La detección de comportamientos anómalos en un sistema multiinquilino plantea retos únicos. Es fundamental mantener el aislamiento de los datos sin comprometer la escalabilidad. El modelo también debe gestionar la escasez de datos y realizar una compleja ingeniería de características para garantizar que se tienen en cuenta las actividades de los usuarios más significativas desde el punto de vista estadístico.
Hemos utilizado con éxito endpoints multimodelo (MME) para trabajar eficazmente a gran escala. Le explicamos cómo.
Perfilado del comportamiento de los usuarios
Para detectar actividades anómalas, primero calculamos perfiles completos del comportamiento de los usuarios. Cada perfil captura distintos patrones de comportamiento de usuarios individuales en todo el entorno. Esto lo hacemos para cada inquilino de forma totalmente independiente, respetando estrictas políticas de cumplimiento de datos.
Este perfil recoge métricas estadísticas clave como la desviación estándar modificada, los valores percentiles y otras métricas derivadas. De este modo, caracterizamos eficazmente la distribución de la actividad de un usuario a lo largo de varios días.
Determinamos que las actividades de los usuarios en la dirección de menor varianza suelen ser los indicadores más relevantes de comportamiento anómalo. Priorizar las variables con menor varianza permite detectar indicios de comportamiento más relevantes y reforzar la resistencia al ruido del modelo.
El método tradicional de modelado recomienda descartar las características de baja varianza, ya que pueden ser menos informativas y susceptibles al ruido. Sin embargo, para modelar el comportamiento de actividad, las características de baja varianza pueden reflejar patrones de comportamiento normal, lo que puede resultar útil para identificar agrupaciones de usuarios con comportamientos similares. Y no se deben ignorar las ligeras variaciones considerándolas como ruido. Por ejemplo, un proxy VPN utilizado por empleados desde una ubicación concreta puede considerarse una característica de baja varianza. Pero un cambio en la dirección IP de acceso podría indicar una posible anomalía.
Aislamiento de datos
La seguridad y la privacidad de los datos fueron consideraciones clave, dado que se trata de un sistema multiinquilino. Garantizamos una estricta segregación de datos para evitar cualquier filtración de información entre inquilinos. El perfil de cada usuario se crea a partir de los datos que pertenecen al inquilino de ese usuario específico. Además, cada uno tiene su propio modelo de aprendizaje automático. Este diseño refuerza el aislamiento de los datos.
Perfiles de inquilino
También elaboramos perfiles de inquilino que caracterizan patrones de comportamiento generales en el entorno del cliente. Los perfiles de inquilino identifican métricas clave como patrones de uso de sitios web, tendencias de actividad y otros atributos comunes en todo el entorno del inquilino. A continuación, combinamos los perfiles usuario con patrones generales de los inquilinos, y entonces mejoramos la capacidad del sistema para distinguir desviaciones legítimas de falsos positivos.
Inferencia
Nuestro proceso de canalización de inferencia evalúa la actividad actual de un usuario dentro de un período de tiempo concreto. Tanto el perfil de comportamiento del usuario como el correspondiente perfil del inquilino se utilizan para calcular una puntuación dinámica de anomalía basada en el patrón de actividad actual del usuario.
Las actividades que se desvían de forma importante se marcan como anomalías. Los eventos anómalos se marcan y se añaden al modelo de datos junto con la capacidad de explicar su relevancia, que finalmente se presenta en la interfaz de usuario como se muestra en la Figura 1 a continuación.
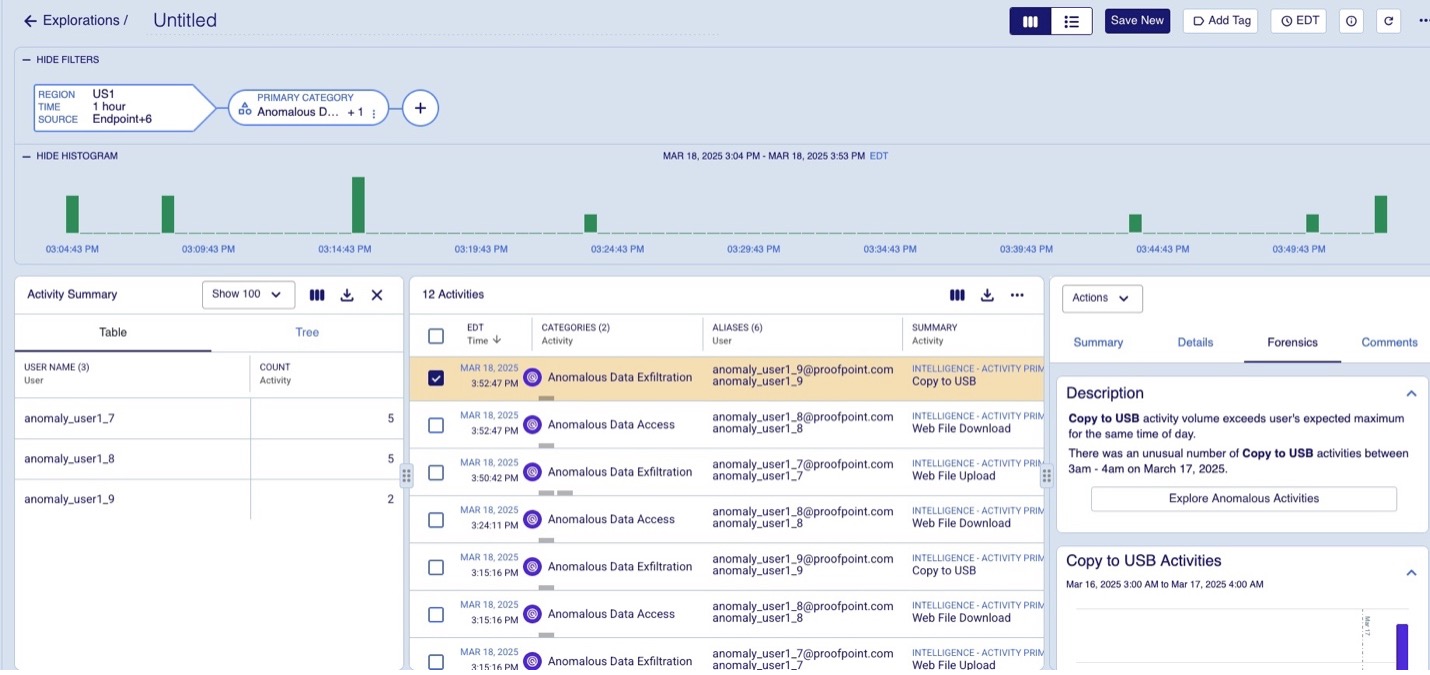
Figura 1: Actividades anómalas marcadas.
Para escalar el sistema de forma eficiente, utilizamos endpoints multimodelo (multimodel endpoints). Nuestra canalización de inferencia se muestra en la Figura 2.
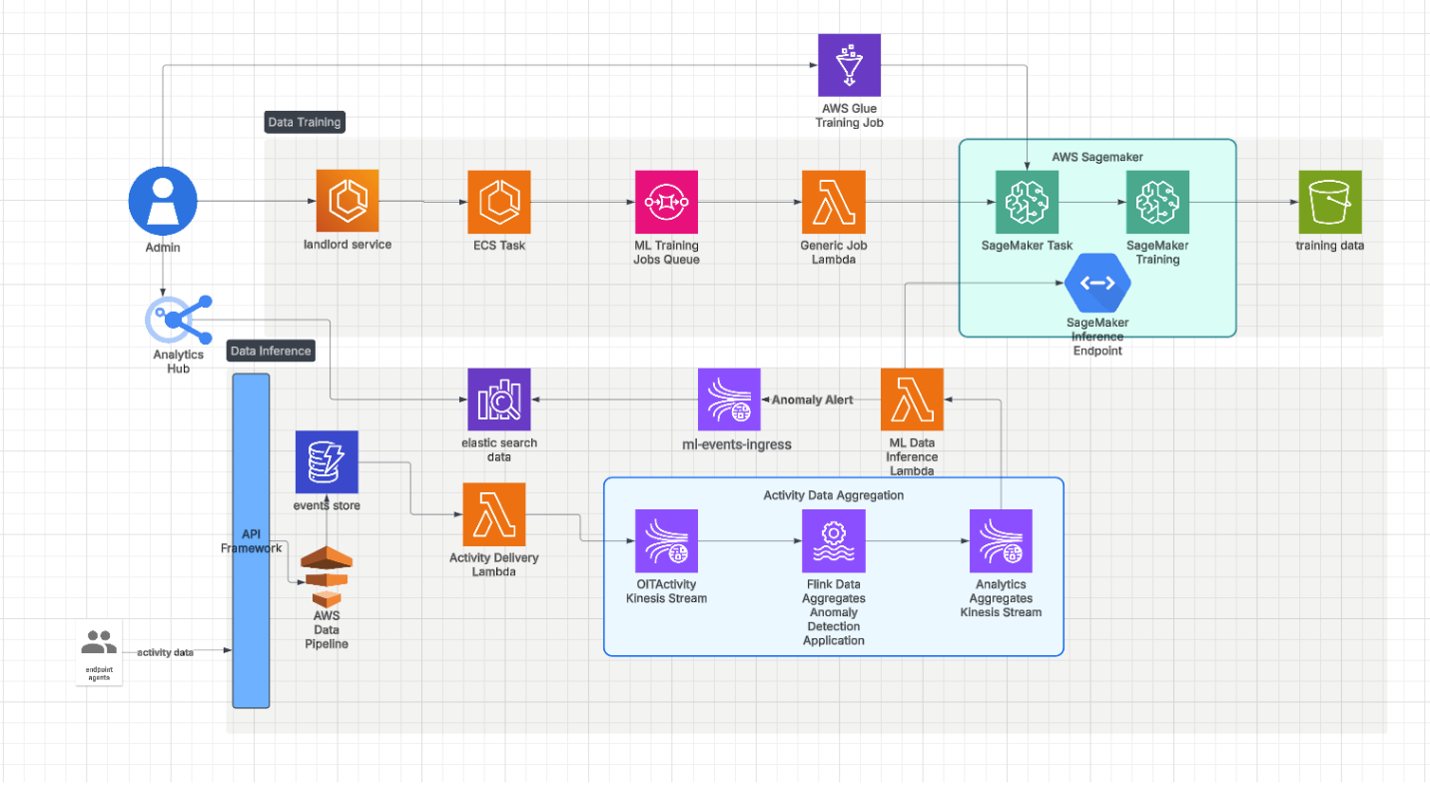
Figura 2: Arquitectura de canalización.
Los endpoints multimodelo permiten alojar varios modelos en un único endpoint. Esto permite cargar y descargar modelos de forma dinámica y bajo demanda. Es un enfoque que reduce drásticamente los costos de infraestructura porque permite sacar el máximo provecho a los recursos.
También logró mantener una latencia baja en el ciclo completo de inferencia en tiempo real, según nuestras pruebas. Cada modelo de aprendizaje automático se almacena en blob y se carga de manera dinámica cuando es necesario. Esto permite cambiar el modelo de forma rápida y eficaz. Los endpoints multimodelo nos permitieron gestionar varios modelos en un único endpoint, facilitando el despliegue. Esto nos permitió escalar sin problemas a medida que aumentaba el número de inquilinos.
Trabajo futuro
En el futuro, tenemos previsto utilizar grandes modelos de lenguaje (LLM) y flujos de trabajo con agentes de IA para mejorar nuestro proceso de detección de anomalías. Asimismo, los grandes modelos de lenguaje podrían generar resúmenes de las actividades en intervalos de tiempo definidos, identificando de forma automática los aspectos clave y las anomalías. De este modo, los analistas de seguridad dispondrían de más información procesable. También permitiría tomar decisiones más rápidas y precisas. Además, los agentes de IA pueden partir de las anomalías detectadas inicialmente para ejecutar flujos de trabajo, como recopilar resultados de análisis de archivos en tiempo real e información sobre el linaje de los datos, con el fin de eliminar falsos positivos.
Únase al equipo
En Proofpoint, consideramos que nuestro personal, con su amplia variedad de experiencias y condicionantes vitales, son la fuerza motriz de nuestro éxito. Nos dedicamos en cuerpo y alma a proteger a las personas, los datos y las marcas contra las amenazas avanzadas actuales y los riesgos de incumplimiento normativo.
Contamos con los mejores profesionales del sector para:
- Crear y ampliar nuestra plataforma de seguridad demostrada.
- Combinar innovación y velocidad en una arquitectura cloud que evoluciona constantemente.
- Analizar nuevas amenazas y ofrecer información detallada a través de inteligencia basada en datos.
- Colaborar con nuestros clientes para resolver los principales retos para su ciberseguridad .
Si está interesado en obtener información sobre las oportunidades de empleo en Proofpoint, visite la página de oportunidades de empleo en Proofpoint.
Acerca de los autores

Ram Kulathumani es jefe de departamento en Proofpoint y dirige la investigación y el desarrollo de aprendizaje automático casos de uso de seguridad impactantes. Su trabajo reciente se ha centrado principalmente en ajustar grandes modelos transformer, diseñar prompts, evaluar grandes modelos de lenguaje y optimizar el rendimiento de la inferencia en sistemas de aprendizaje automático.

Azeem Yousaf es ingeniero sénior de Proofpoint especializado en el desarrollo de soluciones de inteligencia sobre amenazas basadas en IA. Su experiencia abarca el desarrollo de algoritmos básicos y la ingeniería de funciones avanzadas. Fuera del trabajo, Azeem disfruta jugando al críquet en su club local.

Khurram Ghafoor es director sénior de Proofpoint, especializado en arquitectura de plataformas de datos y canalizaciones de inteligencia artificial y aprendizaje automático. Con más de 20 años de experiencia, aporta un profundo conocimiento en desarrollo de software, arquitectura escalable y aplicación de tecnologías de inteligencia artificial y aprendizaje automático.