
“Prospettive di ingegneria” è una serie di articoli del blog che fornisce uno sguardo dietro le quinte sulle problematiche tecniche, le lezioni apprese e i miglioramenti che aiutano i nostri clienti a proteggere i loro collaboratori e i loro dati ogni giorno. Negli articoli che scrivono, i nostri ingegneri spiegano il processo che ha portato a un’innovazione Proofpoint.
Le aziende affrontano costantemente le minacce legate a attività interne. Risulta perciò cruciale identificare i casi in cui i comportamenti degli utenti si discostano dagli schemi abituali. È inoltre essenziale prevenire la fuoriuscita di dati sensibili dall’azienda.
Proofpoint ha progettato una pipeline sofisticata di rilevamento delle anomalie. Oltre a modellare il profilo comportamentale di ogni utente, questa pipeline aggrega informazioni specifiche sui tenant. La precisione del rilevamento e della prevenzione delle minacce vengono così migliorate.
Il rilevamento dei comportamenti anomali in un sistema multi-tenant comporta sfide uniche. Dobbiamo preservare l’isolamento dei dati garantendo la scalabilità. Il modello deve anche gestire la dispersione dei dati e eseguire una complessa ingegnerizzazione delle caratteristiche per garantire che vengano considerate le attività dell'utente più significative dal punto di vista statistico.
Per operare in modo efficiente su larga scala, utilizziamo endpoint a più modelli. Ecco come.
Profilazione del comportamento degli utenti
Per rilevare le attività inusuali, in primo luogo stabiliamo dei profili completi del comportamento degli utenti, ciascuno dei quali acquisisce schemi comportamentali distinti per i singoli utenti del tenant. Ripetiamo l’operazione per ogni tenant in modo totalmente indipendente l’uno dall’altro, rispettando rigorose policy di conformità dei dati.
Questo profilo sintetizza indicatori statistici chiave, come la deviazione standard modificata, i valori percentili e altri indicatori derivati. In questo modo, caratterizziamo in modo efficace la distribuzione dell'attività di un utente su un periodo di diversi giorni.
Abbiamo stabilito che le attività degli utenti a varianza minima sono spesso gli indicatori più critici di un comportamento anomalo. Dando priorità alle caratteristiche a bassa varianza, è possibile identificare i segnali comportamentali più pertinenti, migliorando così la solidità del modello rispetto al rumore.
L’approccio della modellazione tradizionale consiglia di abbandonare le caratteristiche a bassa varianza, in quanto possono essere meno informative e più soggette al rumore. Tuttavia, per la modellazione dei comportamenti legati alle attività, le caratteristiche a bassa varianza possono offrire uno schema di comportamento normale che può rivelarsi utile per identificare cluster di gruppi omologhi. Leggere variazioni non devono essere assimilate a rumore e ignorate. Per esempio, un proxy VPN per gli utenti di un ufficio specifico può essere definito come una bassa varianza, ma un cambiamento dell’indirizzo IP d’accesso può indicare un’anomalia.
Isolamento dei dati
La sicurezza e la privacy dei dati erano considerazioni fondamentali dato che si tratta di un sistema multitenant. Assicuriamo una rigorosa separazione dei dati per prevenire la fuoriuscita di informazioni tra i tenant. Il profilo di ogni utente è stabilito a partire dai dati che appartengono al tenant di quell’utente specifico. Inoltre, ogni tenant ha il suo proprio modello di machine learning (ML). Questo design garantisce un solido isolamento dei dati.
Profili tenant
Abbiamo anche stabilito dei profili tenant che caratterizzano i modelli comportamentali generali nell'ambiente del cliente. I profili tenant identificano gli indicatori chiave come gli schemi di utilizzo dei siti web, le tendenze delle attività e altri attributi legati al tenant. Quindi abbiamo combinato i profili degli utenti con gli schemi più generali del tenant interessato, per poi migliorare la capacità del sistema di distinguere gli scostamenti legittimi dai falsi positivi.
Inferenza
La nostra pipeline di inferenza valuta l’attività attuale di un utente su un periodo definito. Il profilo comportamentale dell’utente e il profilo del tenant corrispondente vengono utilizzati per calcolare un punteggio di anomalia dinamico dell’attività dell’utente.
Le attività che si discostano in modo significativo dagli schermi abituali vengono segnalate come anomalie. Gli eventi anomali vengono quindi segnalati e aggiunti al modello di dati insieme a una spiegazione visibile nell’interfaccia utente come mostrato nella figura 1 qui sotto.
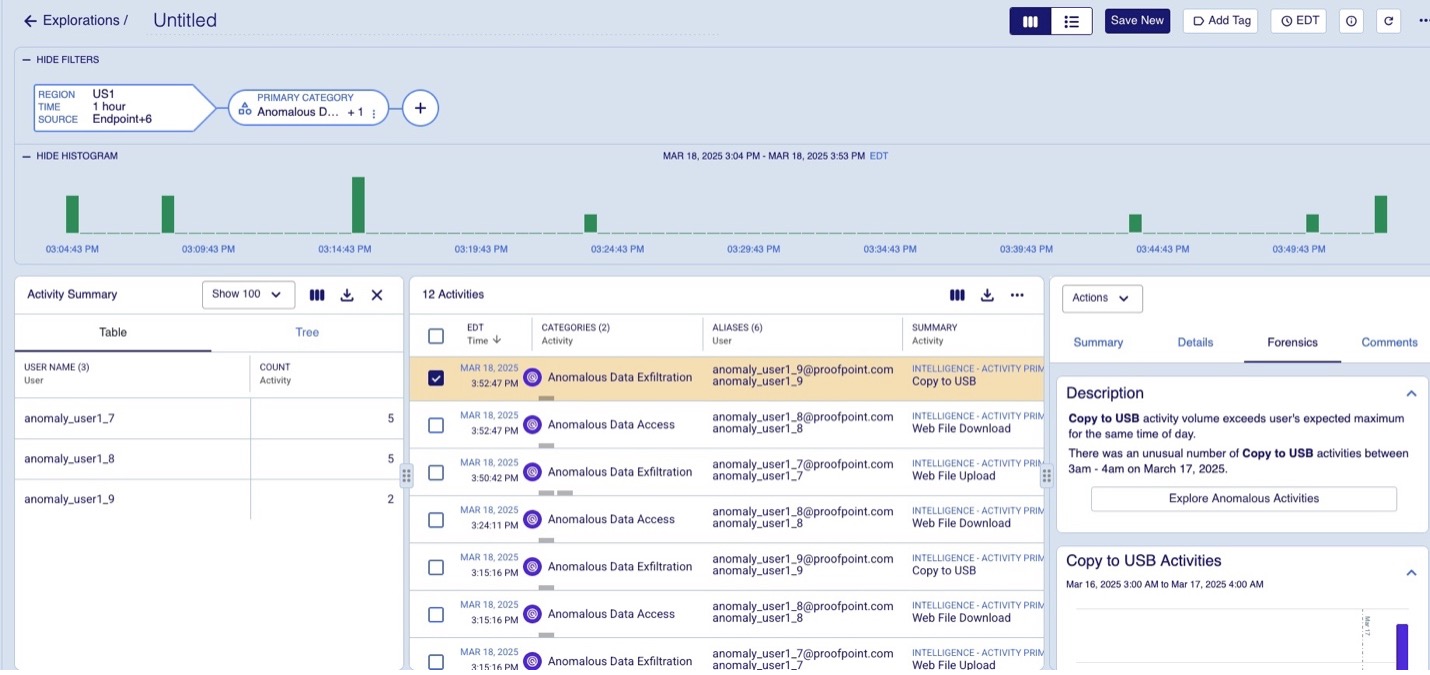
Figura 1. Attività anomale segnalate
Per scalare il sistema in modo efficace abbiamo utilizzato endpoint a più modelli. La nostra pipeline di inferenza è illustrata nella figura 2.
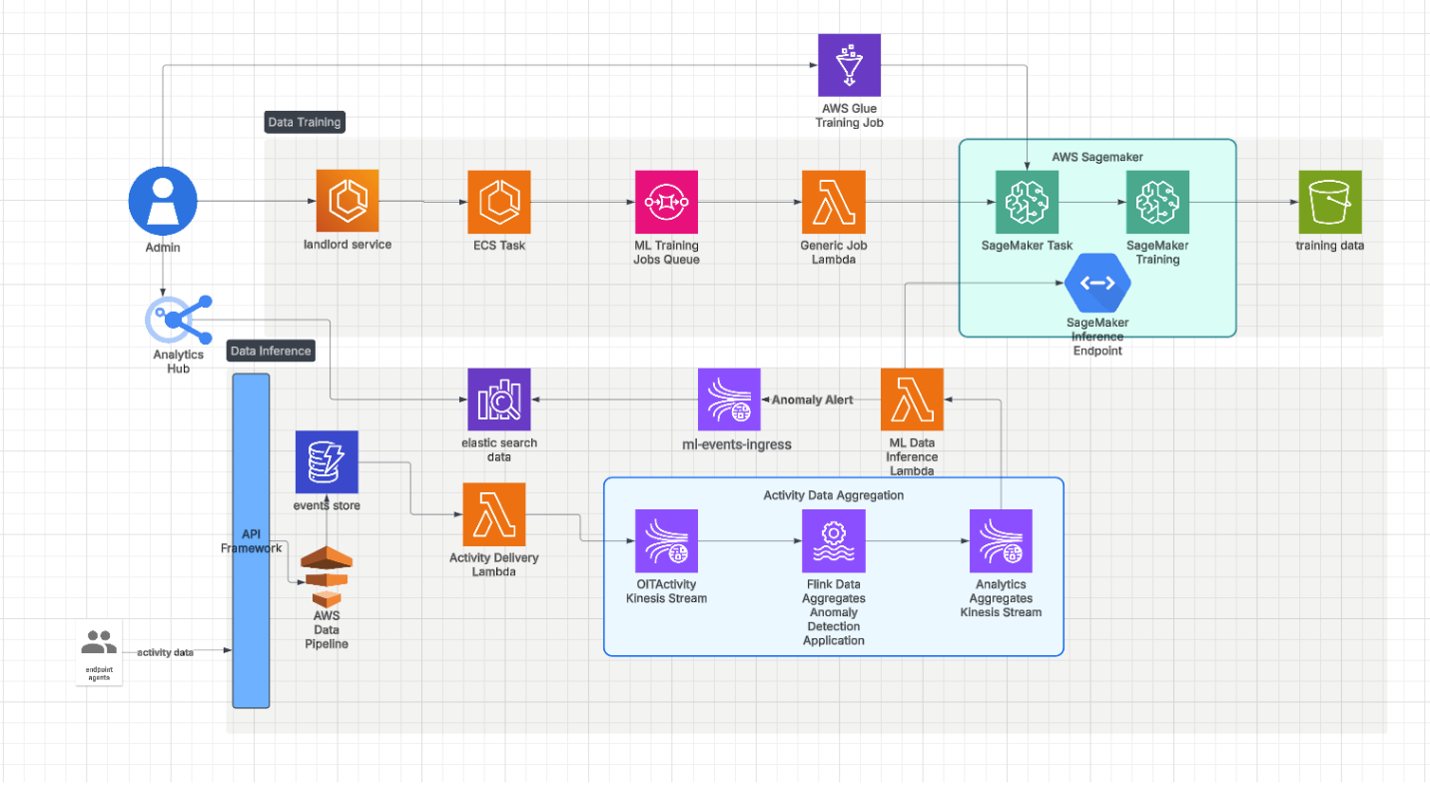
Figura 2. Architettura della pipeline
Gli endpoint a più modelli permettono di ospitare diversi modelli su uno stesso endpoint, per caricare e scaricare i modelli in modo dinamico e su richiesta. Questo approccio riduce in modo significativo i costi infrastrutturali perché permette di ottimizzare l’utilizzo delle risorse.
In base ai nostri test, ha anche mantenuto una bassa latenza per il ciclo d'inferenza in tempo reale. Ogni modello di machine learning (ML) viene archiviato in un blob, ovvero un grande oggetto binario, e caricato dinamicamente quando richiesto, permettendo di cambiare i modelli in modo rapido e efficiente. Gli endpoint a più modelli ci hanno permesso di gestire diversi modelli sotto uno stesso endpoint, razionalizzando la nostra strategia di implementazione. Ciò ci ha permesso di scalare facilmente con l’aumentare del numero di tenant.
Attività future
In futuro, prevediamo di utilizzare modelli linguistici di grandi dimensioni e flussi di lavoro di IA agentica per rafforzare la nostra pipeline di rilevamento delle anomalie. E i modelli linguistici di grandi dimensioni (LLM) potrebbero riassumere le attività su un periodo definito, estraendo automaticamente le informazioni chiave e le anomalie. Gli analisti della sicurezza godrebbero di informazioni più fruibili e il processo decisionale sarebbe più rapido e preciso. Inoltre, gli agent IA possono basarsi sui rilevamenti delle anomalie iniziali per eseguire flussi di lavoro, come la compilazione in tempo reale dei risultati dell’analisi del contenuto dei file e delle informazioni di tracciabilità dei dati per eliminare i falsi positivi.
Unisciti al team Proofpoint
I nostri collaboratori, e la diversità delle loro esperienze e percorsi, sono l’elemento trainante del nostro successo. La nostra missione è proteggere le persone, i dati , e i marchi contro le minacce avanzate attuali e i rischi di non conformità.
Assumiamo i migliori talenti per:
- Sviluppare e migliorare la nostra piattaforma di sicurezza comprovata
- Combinare innovazione e velocità in un’architettura cloud in costante evoluzione
- Analizzare le nuove minacce e offrire informazioni dettagliata grazie a una threat intelligence basata sulle minacce
- Collaborare con i nostri clienti per risolvere le loro sfide di sicurezza informatica più complesse
Se sei interessato a saperne di più sulle opportunità di lavoro in Proofpoint, visita la nostra pagina dedicata.
Informazioni sugli autori

Ram Kulathumani è Senior Manager di Proofpoint. Dirige le attività di ricerca e lo sviluppo sul machine learning per casi d'uso critici relativi alla sicurezza. Recentemente, si è concentrato sul perfezionamento dei modelli di trasformatori di grandi dimensioni, la progettazione dei prompt, la valutazione dei modelli linguistici di grandi dimensioni (LLM) e l’ottimizzazione delle prestazioni d’inferenza del machine learning (ML).

Azeem Yousaf è Senior Engineer di Proofpoint, specializzato nello sviluppo di soluzioni di threat intelligence basate sull’IA. La sua competenza spazia dallo sviluppo di algoritmi di base alla progettazione avanzata delle caratteristiche. Al di fuori dell’attività lavorativa, Azeem gioca a cricket nel suo club locale.

Khurram Ghafoor è Senior Director di Proofpoint, specializzato nell’architettura di piattaforme dei dati e pipeline di IA/machine learning (ML). Con oltre 20 anni di esperienza, è un esperto nello sviluppo di software, nella creazione di architetture scalabili e nell’applicazione delle tecnologie di machine learning e IA.