Engineering Insights is an ongoing blog series that gives a behind-the-scenes look into the technical challenges, lessons and advances that help our customers protect people and defend data every day. Each post is a firsthand account by one of our engineers about the process that led up to a Proofpoint innovation.
At Proofpoint, running a cost-effective, full-text search engine for compliance use cases is an imperative. Proofpoint customers expect to be able to find documents in multi-petabyte archives for legal and compliance reasons. They also need to index and perform searches quickly to meet these use cases.
However, creating full-text search indexes with Proofpoint Enterprise Archive can be costly. So we devote considerable effort toward keeping those costs down. In this blog post, we explore some of the ways we do that while still supporting our customers’ requirements.
Separating mutable and immutable data
One of the most important and easiest ways to reduce costs is to separate mutable and immutable data. This approach doesn’t always fit every use case, but for the Proofpoint Enterprise Archive it fits well.
For archiving use cases—and especially for SEC 17a-4 compliance—data that is indexed can’t be modified. That includes data-like text in message bodies and attachments.
The Proofpoint Enterprise Archive has features that require the storage and mutation of data alongside a message, in accordance with U.S. Securities and Exchange Commission (SEC) compliance. (For example, to which folders a message is a member, and to which legal matters a message pertains.)
To summarize, we have:
- Large immutable indexes
- Small mutable indexes
By separating data into mutable and immutable categories, we can index these datasets separately. And we can use different infrastructure and provisioning rules to manage that data. The use of different infrastructure allows us to optimize the cost independently.
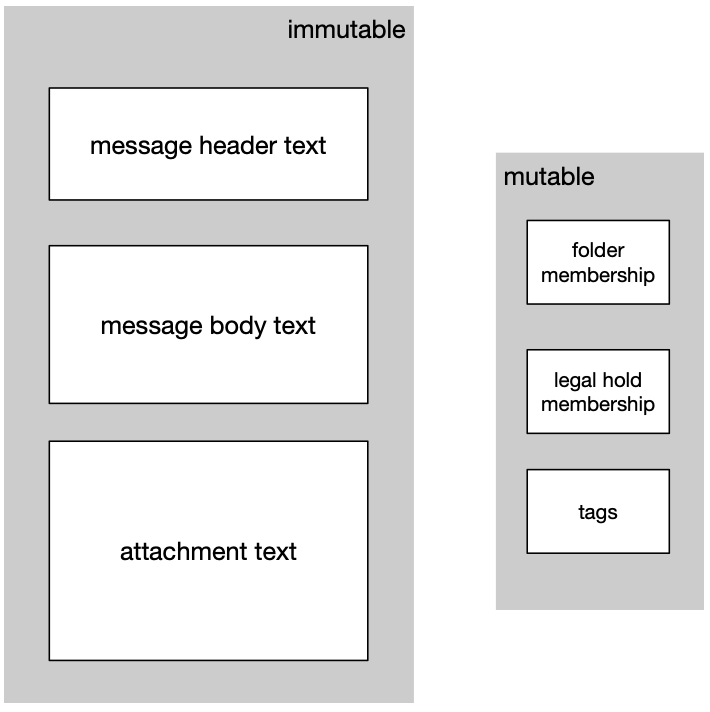
Comparing the relative sizes of mutable and immutable indexes.
Immutable index capacity planning and cost
Normally, full-text search indexes must be provisioned to handle the load of initial write operations, any subsequent update operations and read operations. By indexing immutable data separately, we no longer need to provision enough capacity to handle the subsequent update operations. This requires less IO operations overall.
To reduce IO needs further, the initial index population is managed carefully with explicit IO reservation. Sometimes, this will mean adding more capacity (nodes/servers/VMs) so that the IO needs of existing infrastructure are not overloaded.
When you mutate indexes, it is typically best practice to leave an abundance of disk space to support the index merge operations when updates occur. In some cases, this can be as much as 50% free disk space. But with immutable indexes, you don’t need to have so much spare capacity—and that helps to reduce costs.
In summary, the following designs can help keep costs down:
- Reduce IO needs because documents do not mutate
- Reduce disk space requirements because free space for mutation isn’t needed
- Careful IO planning on initial population, which reduces IO requirements
Mutable index capacity planning and cost
Meanwhile, mutable indexes benefit from standard practices. They can’t receive the same reduced capacity as immutable indexes. However, given that they’re a fraction of the size, it’s a good trade-off.

Comparing the relative free disk space of mutable and Immutable indexes.
Optimized join with custom partitioning and routing
In a distributed database, join operations can be expensive. We often have 10s to 100s of billions of documents for the archiving use case. When both sides of the join operation have large cardinality, it’s impractical to use a generalized approach to join the mutable and immutable data.
To make this high-cardinality join practical, we partition the data in the same way for both the mutable and immutable data. As a result, we end up with a one-to-one relationship between the mutable partitions and the immutable partitions.
Without such a technique, a join operation might look something like this:
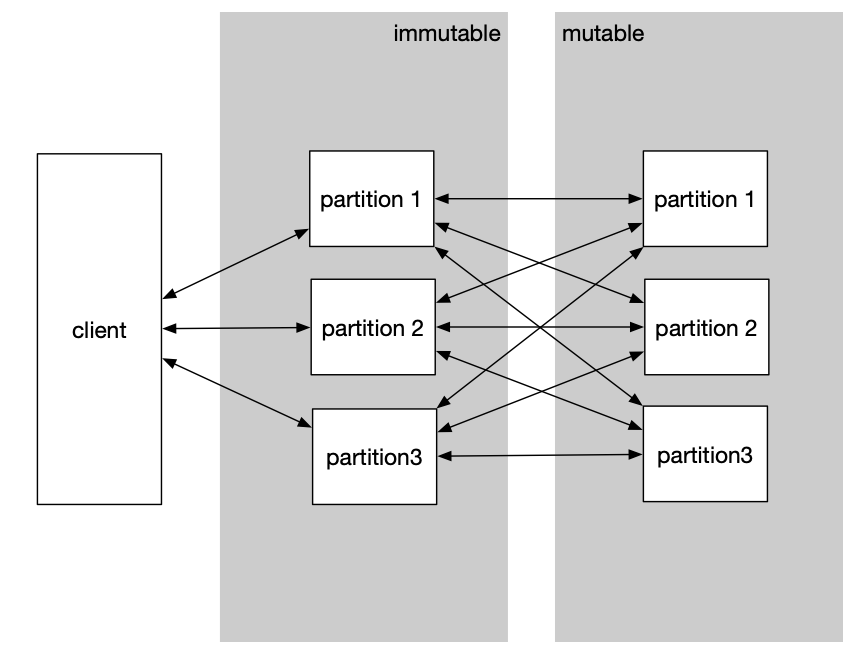
What an unoptimized and generalized join operation looks like.
With custom partitioning and routing, we can reduce the multiplicative searching. And we end up with a pattern like this:
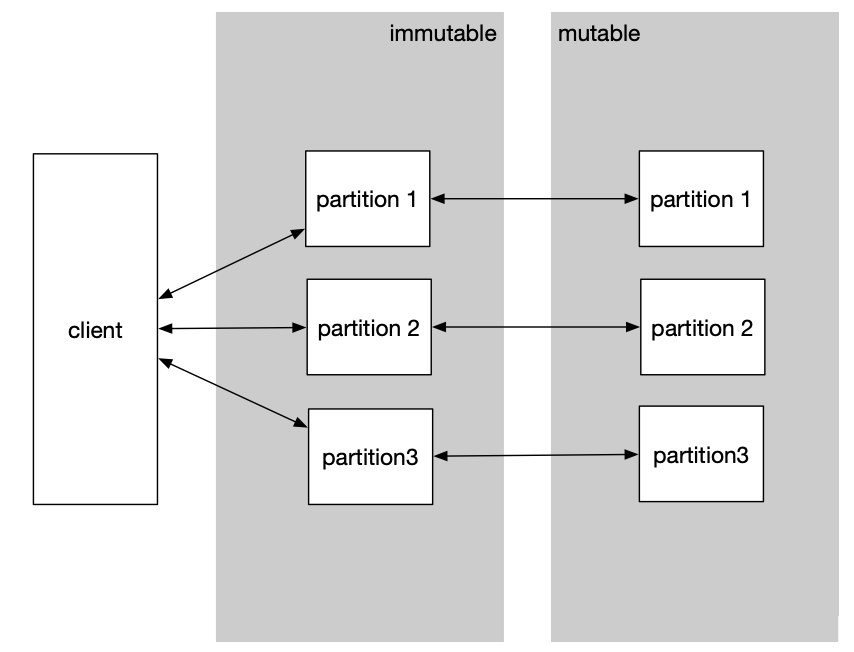
What an optimized join operation looks like.
Compressed search results
To further reduce the amount of data required to transfer during the join operations, we compress the intermediate results. We assign monotonically increasing integer values to documents in each partition. This value is used as the join key.
When searches are performed, each partition of the data can execute in parallel. The results of matching documents are a set of integers. We represent these results using “Roaring Bitsets,” which is a compressed representation. Due to this compression, in some instances the number of bits required per matching items can be as low as 2 bits. Compression reduces the amount of data that needs to be transferred, and it transitively decreases the total time to complete searches.
Final thoughts
We have made several changes to full-text indexing techniques for the Proofpoint Enterprise Archive that help to reduce costs. These costs reductions are significant, and they can be achieved without the need to sacrifice search requirements or performance.
Join the team
At Proofpoint, our people—and the diversity of their lived experiences and backgrounds—are the driving force behind our success. We have a passion for protecting people, data and brands from today’s advanced threats and compliance risks.
We hire the best people in the business to:
- Build and enhance our proven security platform
- Blend innovation and speed in a constantly evolving cloud architecture
- Analyze new threats and offer deep insight through data-driven intelligence
- Collaborate with our customers to help solve their toughest cybersecurity challenges
If you’re interested in learning more about career opportunities at Proofpoint, visit the careers page.
About the author

Jeremiah Ness, a director of engineering at Proofpoint with 20 years of industry experience, is a software and system architect with a pragmatic approach. Passionate about cost reduction, he brings a refreshing inventiveness to solving customer problems.