
Engineering Insights ist eine fortlaufende Blog-Serie, die einen Blick hinter die technischen Herausforderungen sowie auf die Erkenntnisse und Fortschritte wirft, die unseren Kunden im Alltag helfen, ihre Mitarbeiter und Daten zu schützen. Die Beiträge werden von unseren technischen Experten geschrieben und erläutern den Prozess, der zu einer Proofpoint-Innovation geführt hat.
Unternehmen sind ständig Bedrohungen durch Insider-Aktivitäten ausgesetzt. Deshalb ist es wichtig, dass sie ungewöhnliches Anwenderverhalten erkennen und den unerkannten Abfluss vertraulicher Daten verhindern.
Bei Proofpoint haben wir eine moderne Pipeline zur Erkennung von Anomalien entwickelt. Diese modelliert nicht nur Verhaltensprofile zu individuellen Anwendern, sondern aggregiert auch mandantenspezifische Einblicke, sodass Sicherheitsbedrohungen präziser erkannt und zielgerichteter verhindert werden können.
Eine besondere Herausforderung stellt die Erkennung von ungewöhnlichem Verhalten in einem System dar, das von mehreren Mandanten genutzt wird. Wir müssen einerseits Datenisolierung und gleichzeitig Skalierbarkeit gewährleisten. Darüber hinaus muss das Modell bei knappen Datenbeständen funktionieren, aber auch komplexe Methoden zur Merkmalskonstruktion (Feature Engineering) beherrschen, um die statistisch signifikantesten Anwenderaktivitäten zu berücksichtigen.
Wir haben erfolgreich Multimodel-Endpunkte (MME) eingesetzt, um auch hinsichtlich der Skalierung effizient zu arbeiten. Hier erfahren Sie, wie das funktioniert.
Erstellung von Anwenderverhaltensprofilen
Für die Erkennung ungewöhnlicher Aktivitäten berechnen wir zunächst umfassende Anwenderverhaltensprofile. Jedes dieser Profile erfasst die spezifischen Verhaltensmuster eines einzelnen Anwenders, wobei für jeden Anwender des Mandanten ein Profil erstellt wird. Dies erfolgt für jeden Mandanten komplett separat und unter Einhaltung strenger Datenschutzrichtlinien.
Das Profil beinhaltet wichtige statistische Kennzahlen wie die modifizierte Standardabweichung, Perzentilwerte und andere abgeleitete Kennzahlen, mit deren Hilfe wir die Aktivitäten eines Anwenders über einen Zeitraum von mehreren Tagen hinweg effektiv charakterisieren können.
Dabei haben wir festgestellt, dass Anwenderaktivitäten mit besonders geringer Varianz oft die wichtigsten Indikatoren für ungewöhnliches Verhalten sind. Durch die Priorisierung von Merkmalen mit geringer Varianz können wir aussagekräftigere verhaltensbasierte Signale identifizieren und damit die Rauschanfälligkeit des Modells reduzieren.
Der traditionelle Modellierungsansatz empfiehlt, Merkmale mit geringer Varianz zu ignorieren, weil sie häufig weniger Aussagekraft haben und anfälliger für Rauschen sein können. Bei der Modellierung von Aktivitätsverhalten können Merkmale mit geringer Varianz jedoch ein normales Verhaltensmuster liefern, das bei der Identifizierung von Peer-Group-Clustern helfen kann. Leichte Abweichungen dürfen dabei nicht als Rauschen ignoriert werden. So kann beispielsweise ein VPN-Proxy für Büroanwender an einem bestimmten Standort als geringe Varianz gewertet werden, eine Änderung der IP-Adresse der Zugriffsquelle jedoch auf eine Anomalie hindeuten.
Datenisolierung
Da das System von mehreren Mandanten genutzt wird, waren Datensicherheit und Datenschutz wichtige Aspekte. Wir haben auf die strikte Trennung der Daten geachtet, um Informationsabflüsse zwischen Mandanten zu verhindern. Das Profil jedes Anwenders wird aus den Daten erstellt, die zum Mandanten des jeweiligen Anwenders gehören. Darüber hinaus verfügt jeder Mandant über ein eigenes ML-Modell (Machine Learning). Dieses Konzept gewährleistet die strikte Datenisolierung.
Mandantenprofile
Wir haben auch Mandantenprofile berechnet, die allgemeine Verhaltensmuster innerhalb der gesamten Mandantenumgebung charakterisieren. Diese Profile identifizieren wichtige Kennzahlen wie Website-Nutzungsmuster, Aktivitätstrends und andere mandantenspezifische Attribute. Anschließend haben wir die Anwenderprofile mit breiteren Mandantenmustern kombiniert und die Fähigkeit des Systems verbessert, legitime Abweichungen von False Positives zu unterscheiden.
Inferenz
Unsere Inferenz-Pipeline analysiert die aktuellen Aktivitäten eines Anwenders innerhalb eines definierten Zeitfensters. Anhand des Anwenderverhaltensprofils und des zugehörigen Mandantenprofils wird ein dynamischer Anomaliewert für das aktuelle Aktivitätsmuster des Anwenders berechnet.
Aktivitäten, die erheblich abweichen, werden als Anomalien gekennzeichnet. Daraufhin werden ungewöhnliche Ereignisse gekennzeichnet, dem Datenmodell zusammen mit der Erklärbarkeit hinzugefügt und anschließend in der Anwenderoberfläche wie in Abbildung 1 dargestellt.
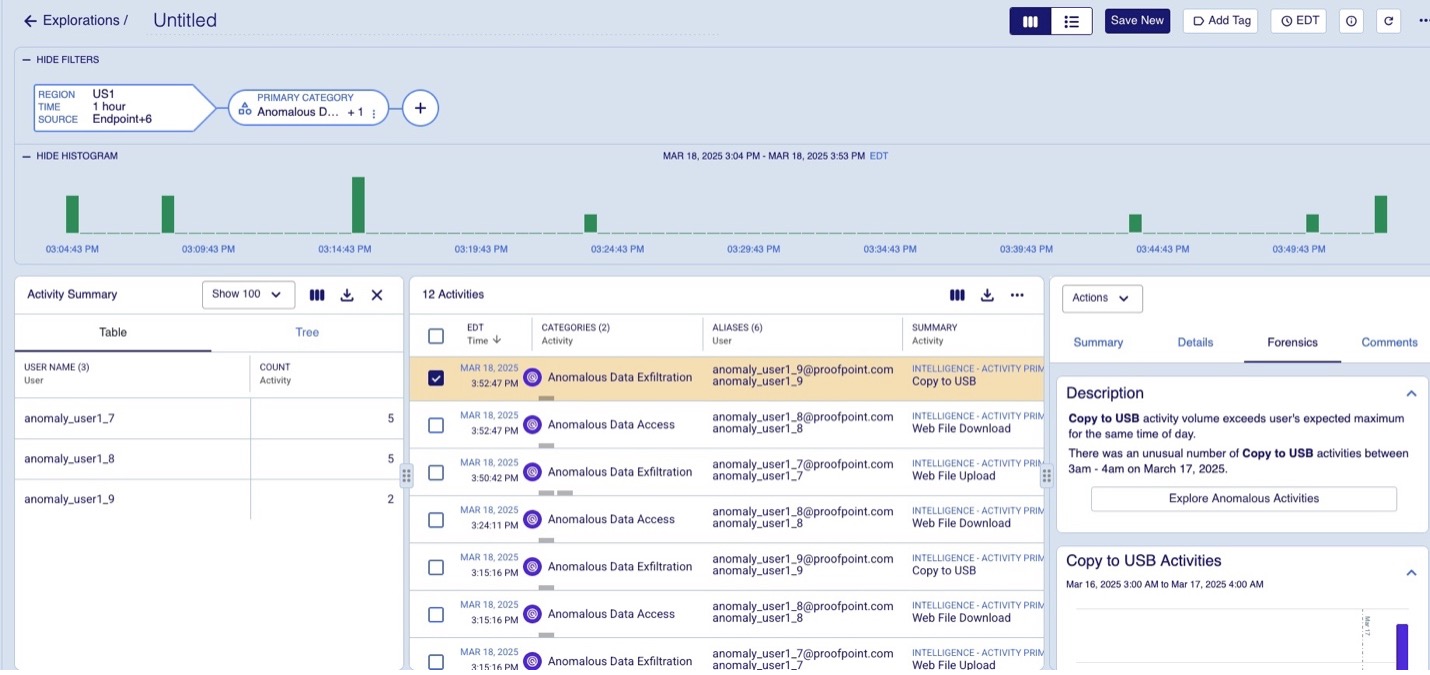
Abb. 1: Gekennzeichnete ungewöhnliche Aktivitäten.
Für die effiziente Skalierung des Systems haben wir auf Multimodel-Endpunkte zurückgegriffen. Abbildung 2 zeigt unsere Inferenz-Pipeline.
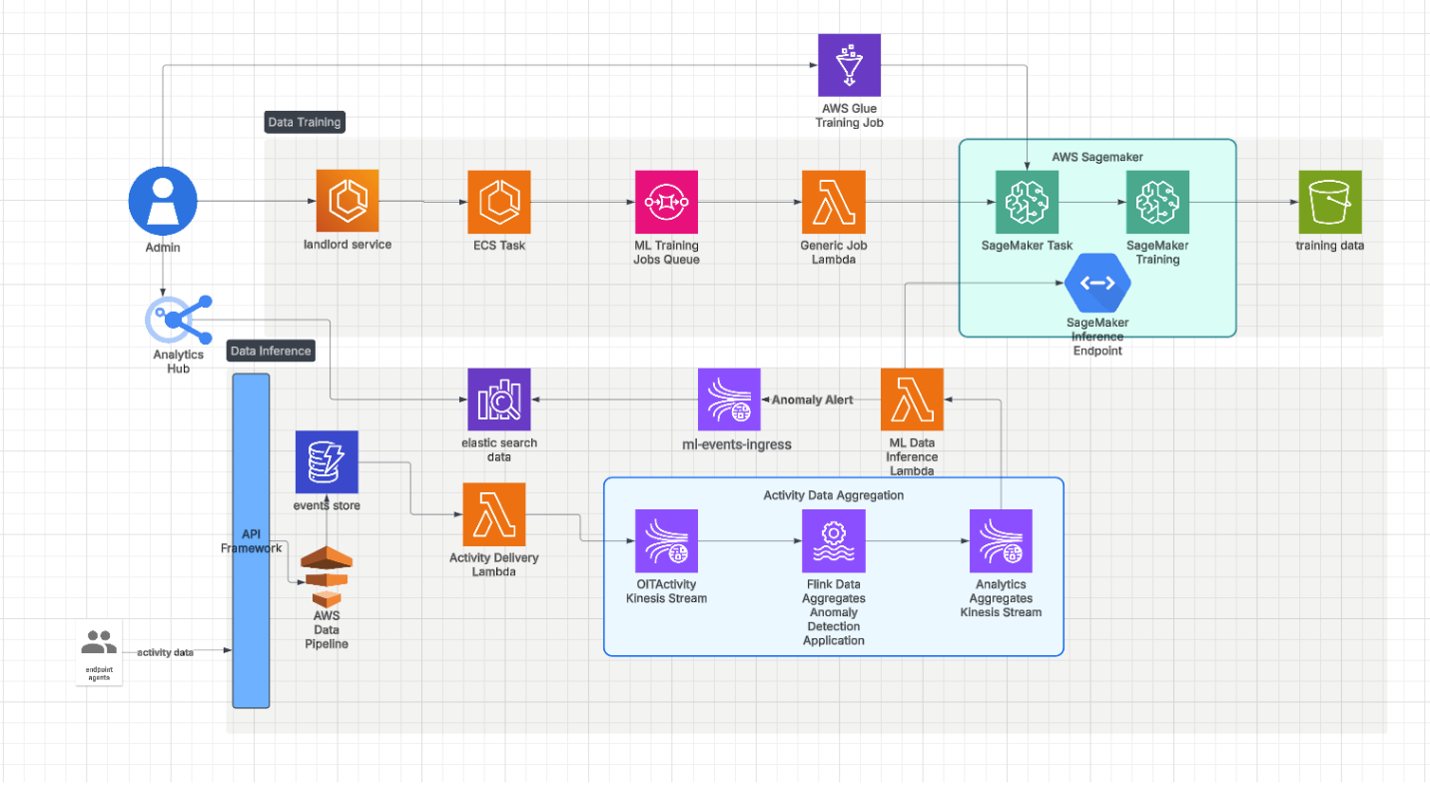
Abb. 2: Pipeline-Architektur.
Mit MMEs können mehrere Modelle auf einem einzigen Endpunkt gehostet und Modelle dynamisch on-demand geladen und entladen werden. Dieser Ansatz optimiert die Ressourcennutzung und führt dadurch zu einer deutlichen Senkung der Infrastrukturkosten.
Darüber hinaus hält er die Latenz für Echtzeit-Inferenz-Roundtrips auf einem niedrigen Niveau. Da jedes ML-Modell im Blob-Speicher abgelegt und bei Bedarf dynamisch geladen wird, sind schnelle und effiziente Modellwechsel möglich. Dank der MMEs lassen mehrere Modelle unter einem einzigen Endpunkt verwalten. Dadurch konnten wir unsere Bereitstellungsstrategie optimieren und bei steigenden Mandantenzahlen nahtlos skalieren.
Pläne für die Zukunft
In Zukunft möchten wir LLMs und KI-Agenten-Workflows nutzen, um unsere Pipeline zur Erkennung von Anomalien zu erweitern. Darüber hinaus könnten Large Language Models (großes Sprachmodelle, LLMs) Aktivitäten innerhalb bestimmter Zeitfenster zusammenfassen und automatisch wichtige Erkenntnisse und Anomalien extrahieren, um Sicherheitsanalysten mehr entscheidungsrelevante Informationen zu liefern sowie schnellere und genauere Entscheidungen zu ermöglichen. Zudem können KI-Agenten die ersten Erkenntnisse über Anomalien nutzen, um Workflows auszuführen und zum Beispiel Echtzeit-Scanergebnisse für Dateiinhalte und Informationen zur Datenabfolge zusammenzustellen, um False Positives auszusortieren.
Werden Sie Teil unseres Teams
Unsere Mitarbeiter mit ihren vielfältigen Erfahrungen und Hintergründen sind für den Erfolg unseres Unternehmens maßgeblich. Wir setzen uns mit großem Engagement dafür ein, Mitarbeiter, Daten und Marken vor den hochentwickelten Bedrohungen und Compliance-Risiken von heute zu schützen.
Wir suchen die besten Mitarbeiter der Branche für folgende Aufgabenbereiche:
- Entwicklung und Verbesserung unserer bewährten Sicherheitsplattform
- Kombination von Innovation und Schnelligkeit in einer sich ständig weiterentwickelnden Cloud-Architektur
- Analyse neuer Bedrohungen und Bereitstellung umfassender Einblicke durch datenbasierte Bedrohungsinformationen
- Zusammenarbeit mit unseren Kunden, um die größten Herausforderungen im Bereich Cybersicherheit zu bewältigen
Weitere Informationen über die Karrieremöglichkeiten bei Proofpoint finden Sie auf der Jobs und Karriere-Seite.
Informationen zu den Autoren

Ram Kulathumani ist Senior Manager bei Proofpoint und leitet die ML-Forschung und -Entwicklung für relevante Sicherheitsanwendungsfälle. In letzter Zeit konzentrierte er sich vor allem auf das Optimieren großer Transformer-Modelle, das Prompt-Engineering, die Analyse von LLMs und die Optimierung der ML-Inferenzleistung.

Azeem Yousaf ist Senior Engineer bei Proofpoint und hat sich auf die Entwicklung von KI-gesteuerten Bedrohungsdatenlösungen spezialisiert. Seine Kompetenzen erstrecken sich auf die Entwicklung von Kernalgorithmen und die Konstruktion komplexer Merkmale. In seiner Freizeit spielt Azeem Yousaf gerne Cricket in seinem örtlichen Verein.

Khurram Ghafoor ist Senior Director bei Proofpoint und hat sich auf die Architektur von Datenplattformen und KI/ML-Pipelines spezialisiert. Mit über 20 Jahren Erfahrung bringt er seine Expertise in den Bereichen Softwareentwicklung, skalierbare Architekturen sowie Anwendung von ML- und KI-Technologien ein.