
Le aziende faticano sempre più a proteggere le informazioni aziendali critiche come la proprietà intellettuale e i segreti commerciali. Questo perché i sistemi di vecchia generazione di sicurezza dei dati sono stati concepiti principalmente per identificare e proteggere i tipi di dati strutturati, come informazioni di identificazione personale, informazioni di identificazione sanitaria e dati della carta di credito. Questi sistemi non sono in grado di comprendere i dati non strutturati, in particolare i documenti, perché si concentrano su elementi di dati discreti piuttosto che sul contesto o sullo scopo più ampio delle informazioni. Un aspetto critico è che faticano a identificare i documenti aziendali sensibili, a meno che questi non corrispondano a modelli predefiniti.
I classificatori basati sull'IA cambiano questa situazione. Questi classificatori utilizzano modelli linguistici di grandi dimensioni (LLM) addestrati su grandi set di dati di documenti aziendali. Grazie a questo addestramento, imparano a riconoscere tipologie di documenti caratterizzati da sfumature specifiche, come segreti commerciali, moduli sanitari, documenti di conformità e accordi legali. I classificatori ottimizzati dall’IA vanno oltre le semplici parole chiave. Invece, utilizzano la comprensione del contesto e della semantica per classificare i documenti in base alla funzione aziendale e all'intento. Quando vengono ulteriormente addestrati sui dati di un'azienda, questi classificatori ad apprendimento automatico si adattano al linguaggio, alla struttura e ai flussi di lavoro unici dell'azienda. Sviluppano continuamente la loro capacità di identificare dove risiedono le informazioni critiche e come si spostano. Ciò consente di implementare strategie di protezione dei dati più precise e proattive.
Cosa sono i classificatori pre-addestrati?
I classificatori pre-addestrati di Proofpoint forniscono un modo efficace per identificare e proteggere i documenti aziendali critici. Includono codice sorgente, documenti contabili e fiscali, file dei collaboratori, accordi e contratti. I nostri classificatori ottimizzati dall’IA sono alimentati da LLM che categorizzano i documenti alla velocità della rete. Combinando modelli di IA open source con algoritmi proprietari e un processo che consente di convalidare i risultati, Proofpoint è in grado di identificare lo scopo di un documento e categorizzarlo con una sicurezza dell'85% o superiore.
È possibile utilizzare classificatori LLM pre-addestrati nelle policy DLP per proteggere contenuti nuovi o precedentemente trascurati, senza la necessità di una classificazione preventiva, risparmiando tempo e fatica. Se combinati con la corrispondenza dei modelli, i classificatori LLM aiutano anche a ridurre i falsi positivi. Ad esempio, con Proofpoint Enterprise DLP, puoi consentire al tuo team delle risorse umane di condividere internamente documenti sensibili, rimuovendo automaticamente le autorizzazioni se tali documenti sono condivisi all'esterno del team.
Gli avvisi arricchiti tramite LLM consentono agli analisti di gestire e analizzare gli incidenti più rapidamente. Ad esempio, se un avviso viene attivato dalla corrispondenza di modelli di numeri della previdenza sociale, Proofpoint Enterprise DLP può identificare se il documento si riferisce alle imposte sui redditi, un modulo di un paziente o una richiesta di credito.
Tuttavia, i classificatori LLM pre-addestrati possono presentare dei limiti. Basandosi su dati aziendali statici ed etichette fisse, faticano ad adattarsi a minacce in evoluzione, contesti aziendali che mutano o scopi dei documenti. Questo può portarli a trascurare segnali sottili, con il rischio di errori di classificazione o falsi positivi. Ecco perché i classificatori ad apprendimento automatico sono sempre più fondamentali.
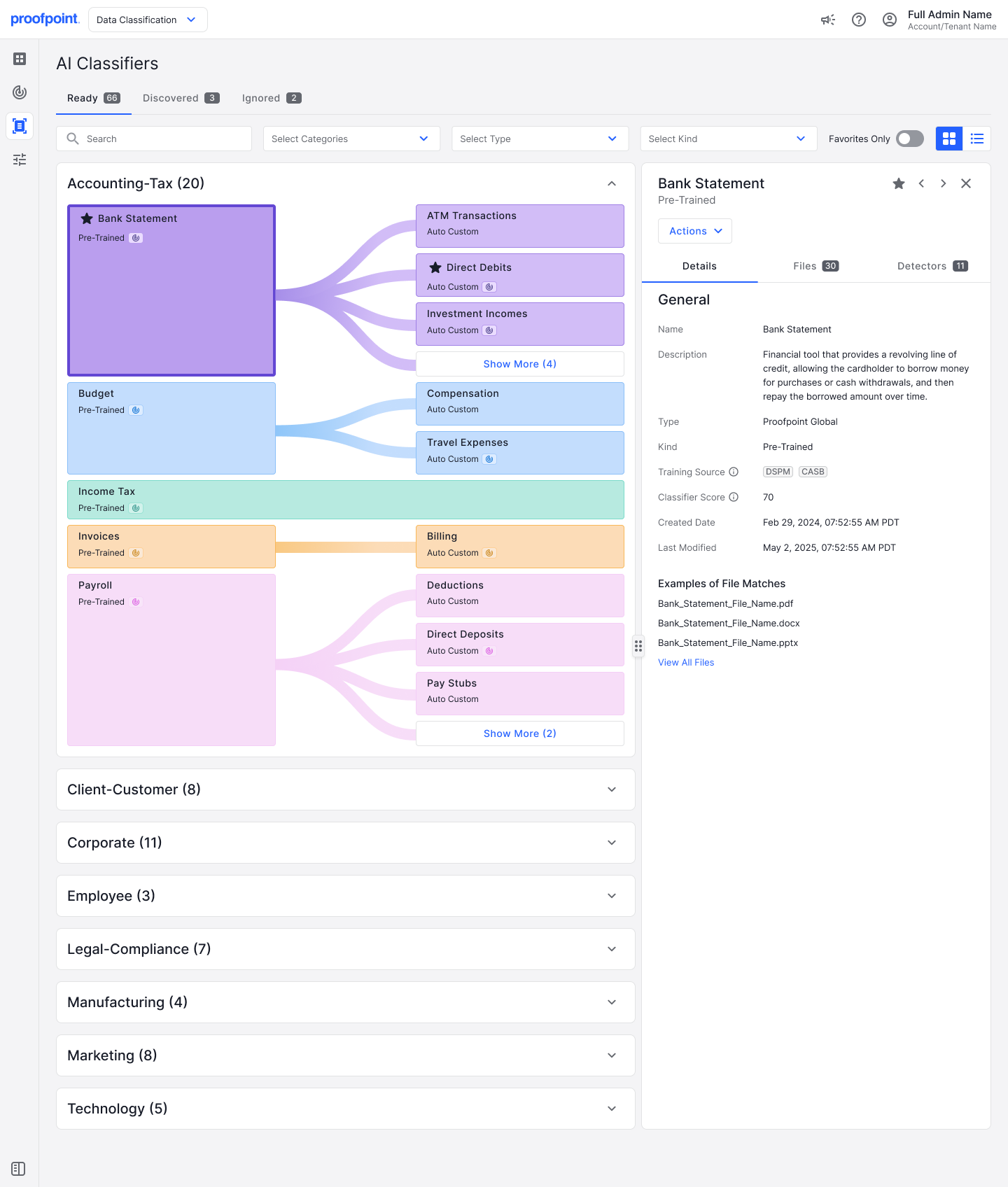
Figura 1. Classificatore IA pre-addestrato per l'estratto conto bancario nella categoria dei documenti contabili-fiscali.
Cosa sono i classificatori ad apprendimento automatico?
I classificatori ad apprendimento automatico di Proofpoint sono progettati per identificare informazioni nuove o uniche per la tua azienda. Si adattano continuamente osservando le interazioni in tempo reale, i modelli di accesso e il contesto comportamentale. Ciò si traduce in una classificazione dei dati più accurata, dinamica e resiliente, con un input umano minimo.
Basandosi su classificatori LLM pre-addestrati, i classificatori ad autoapprendimento perfezionano dinamicamente i propri modelli osservando i modelli nascosti dei dati di un'azienda. Utilizzando l'IA generativa, possono prevedere e assegnare automaticamente nomi a nuove categorie di dati e documenti. Questi potrebbero includere nuovi formati di dati a carattere personale o nuovi documenti di ricerca.
Questo approccio basato sull'IA consente alla nostra soluzione di sicurezza dei dati di migliorare continuamente la precisione della classificazione in base al contesto dei dati in tempo reale, riducendo i falsi positivi e le lacune nella copertura. Integrandosi perfettamente con Proofpoint Enterprise DLP e Proofpoint Data Security Posture Management, non solo classifica i contenuti sensibili, ma applica anche protezioni adattive in tempo reale. Queste protezioni includono la revoca di privilegi di accesso eccessivi o la segnalazione di categorie di documenti o dati ad alto rischio. Il risultato è una difesa completamente automatizzata e scalabile contro lasottrazione e l'esposizione dei dati.
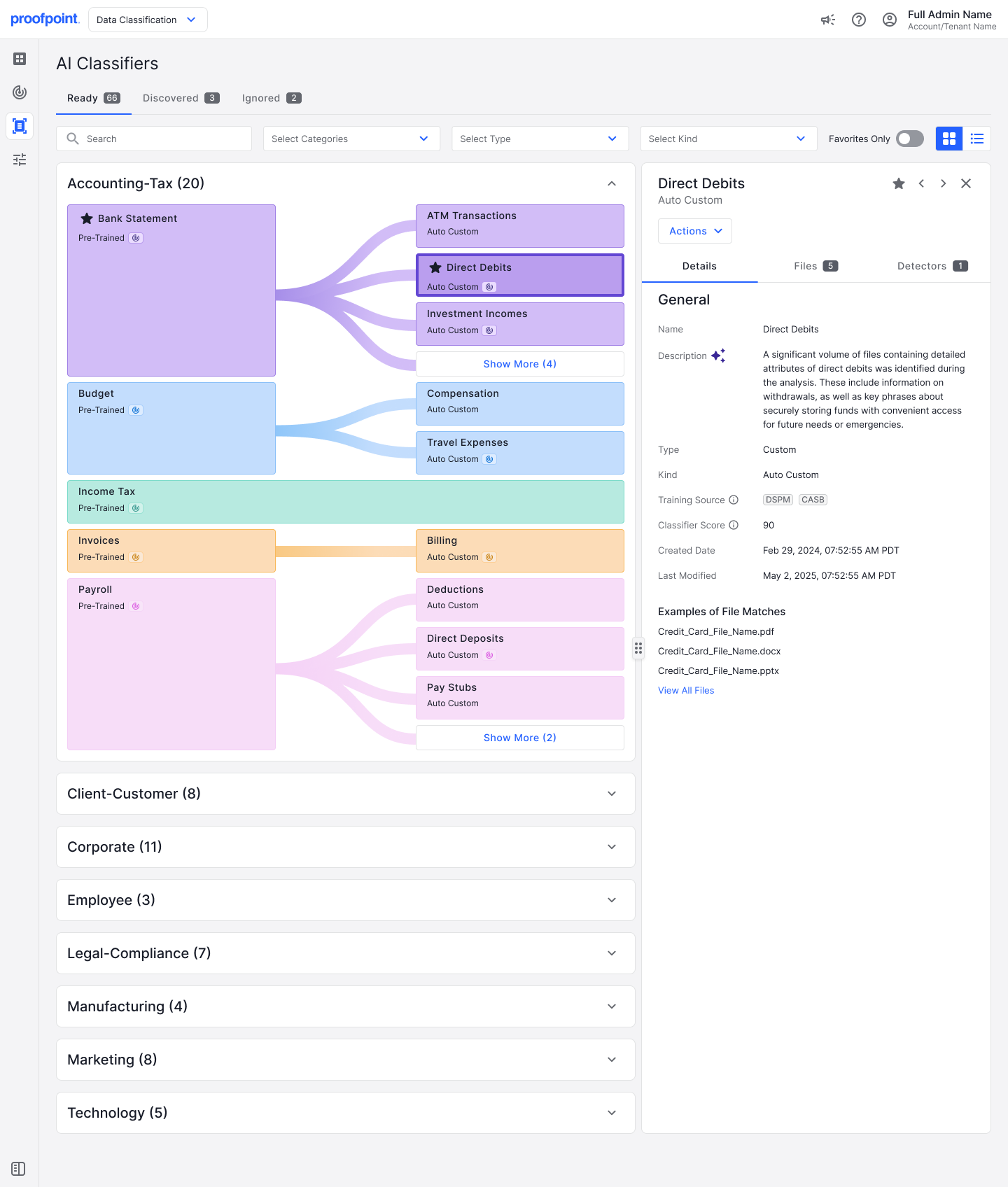
Figura 2. Classificatore IA ad apprendimento automatico e denominato per gli addebiti diretti, una sottocategoria nella categoria Estratti conto bancari.
In che modo i classificatori ad apprendimento automatico ti aiutano a trovare il giusto equilibrio tra innovazione e privacy?
I classificatori ad apprendimento automatico apprendono dai modelli comportamentali e dai segnali contestuali senza esporre contenuti sensibili. Condividendo solo informazioni anonime o aggregate, riducono i rischi per la privacy migliorando al contempo la precisione della classificazione. Questo approccio consente di proteggere i dati in modo adattivo senza compromettere la riservatezza o la conformità normativa.
In che modo l'approccio unificato alla sicurezza dei dati basato sull'IA di Proofpoint aiuta?
La classificazione dei dati e dei documenti ottimizzata dall’IA è il primo passo essenziale verso una sicurezza e una conformità dei dati più intelligenti e basata su agenti. Opera come fosse il sistema sensoriale della tua azienda, consentendo agli agenti di sicurezza automatizzati (il sistema nervoso) di vedere, comprendere e rispondere ai rischi. Dando un senso ai dati, questi classificatori consentono agli agenti di sicurezza di agire con intelligenza e precisione.
Senza una classificazione accurata, gli agenti IA non dispongono del contesto necessario per applicare le politiche, rilevare le anomalie o rispondere alle minacce. I classificatori IA risolvono questo problema identificando informazioni sensibili (dati di identificazione personale e sanitaria, dati della carta di credito, codice sorgente e documenti nuovi o unici per la tua azienda) su applicazioni cloud, endpoint, email e storage. Consentono la categorizzazione e l'etichettatura in tempo reale. Questo guida le azioni a valle come il blocco di trasferimenti di file rischiosi, la revoca dell'accesso, l'escalation di incidenti interni o l'applicazione della crittografia.
Man mano che gli ambienti diventano più complessi e dinamici, la classificazione basata sull'IA può scalare per gestire petabyte di dati e milioni di file e messaggi. Possono fornire informazioni continue sui sistemi di sicurezza agentici. A loro volta, gli agenti IA possono modificare le policy e le risposte in base al livello di sicurezza della classificazione, alla gravità e alla mappatura normativa. Questo aiuta a garantire la conformità a framework come il regolamento generale sulla protezione dei dati (GDPR), le leggi HIPAA (Health Insurance Portability and Accountability Act) e CCPA (California Consumer Privacy Act), senza la necessità di una continua riconfigurazione manuale.
Proprio come il corpo non può reagire ai pericoli senza input sensoriali, la sicurezza autonoma dei dati non può funzionare senza capire quali dati e documenti sta proteggendo. La classificazione ottimizzata dall'IA fornisce la visione e la consapevolezza che consentono agli agenti di sicurezza e conformità di agire in modo rapido, accurato e su larga scala.
Per saperne di più
Per saperne di più sui nostri classificatori ottimizzati dall'IA e sulle soluzioni di sicurezza dei dati di Proofpoint, guarda il webinar Defend Data Innovations.