
Engineering Insights is an ongoing blog series that gives a behind-the-scenes look into the technical challenges, lessons and advances that help our customers protect people and defend data every day. Each post is a firsthand account by one of our engineers about the process that led up to a Proofpoint innovation.
Cyber threats are increasing in their frequency and sophistication. And for a cybersecurity firm like Proofpoint, staying ahead of threats requires us to deploy new machine learning (ML) models at an unprecedented pace. The complexity and sheer volume of these models can be overwhelming.
In previous blog posts, we discussed our approach to ML with Proofpoint Aegis, our threat protection platform. In this blog, we look at Nebula, our next-generation ML platform. It is designed to provide a robust solution for the rapid development and deployment of ML models.
The challenges
We live and breathe supervised machine learning at Proofpoint. And we face active adversaries who attempt to bypass our systems. As such, we have a few unique considerations for our ML process:
- Speed of disruption. Attackers move fast, and that demands that we be agile in our response. Manual tracking of attacker patterns alone isn’t feasible; automation is essential.
- Growing complexity. Threats are becoming more multifaceted. As they do, the number of ML models we need escalates. A consistent and scalable modelling infrastructure is vital.
- Real-time requirements. It is essential to block threats before they can reach their intended targets. To be effective on that front, our platform must meet unique latency needs and support optimised deployment options for real-time inference.
In other ML settings, like processing medical radiographs, data is more stable, so model quality can be expected to perform consistently over time. In the cybersecurity setting, we can’t make such assumptions. We must move fast to update our models as new cyber attacks arise.
Below is a high-level overview of our supervised learning process and the five steps involved.
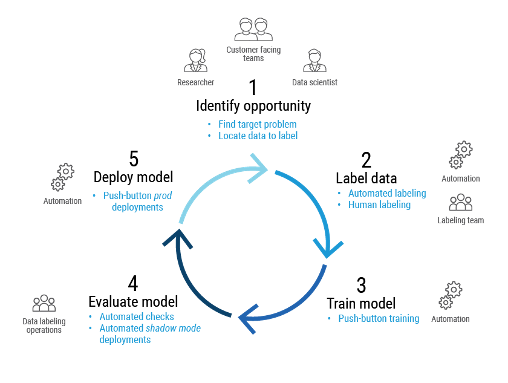
A supervised learning workflow, showing steps 1-5.
Data scientists want to optimise this process so they can bootstrap new projects with ease. But other stakeholders have a vested interest, too. For example:
- Project managers need to understand project timelines for new systems or changes to existing projects.
- Security teams prefer system reuse to minimise the complexity of security reviews and decrease the attack surface.
- Finance teams want to understand the cost of bringing new ML systems online.
Proofpoint needed an ML platform to address the needs of various stakeholders. So, we built Nebula.
The Nebula solution
We broke the ML lifecycle into three components—modelling, training and inference. And we developed modular infrastructure for each part. While these parts work together seamlessly, engineering teams can also use each one independently.
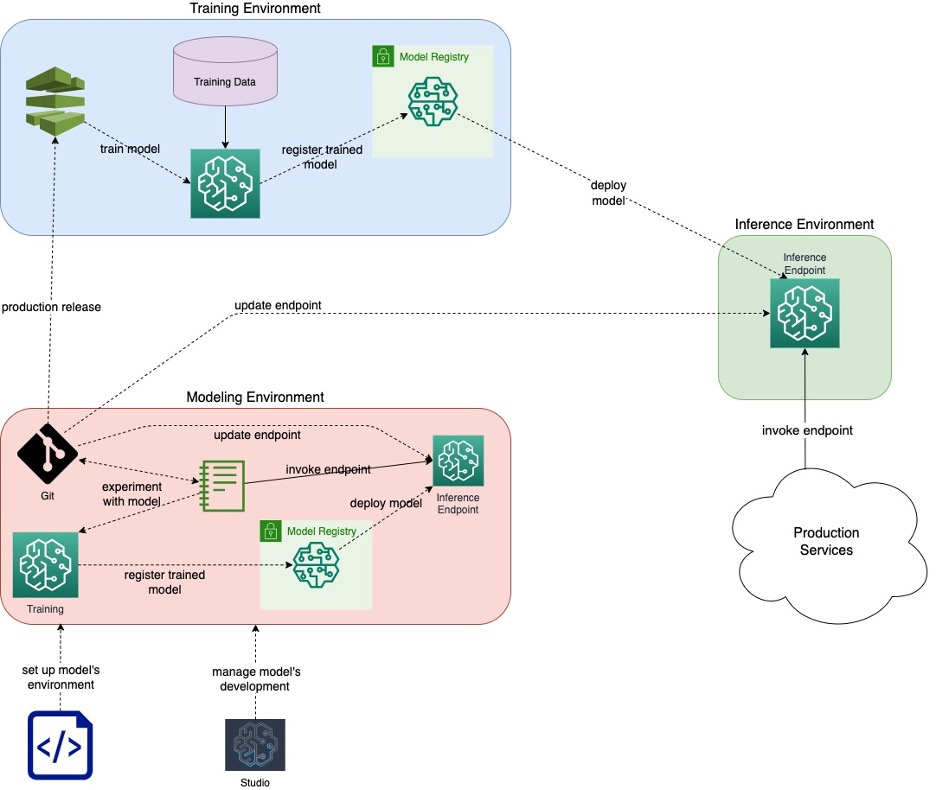
The three modules of the Nebula platform—modelling, training and inference.
These components are infrastructure as code. So, they can be deployed in multiple environments for testing, and every team or project can spin up an isolated environment to segment data.
Nebula is opinionated. It’s “opinionated” because “common use cases” and “the right thing” are subjective and hence require an opinion on what qualifies as such. It offers easy paths to deploy common use cases with the ability to create new variants as needed. The platform makes it easy to do the right thing—and hard to do the wrong thing.
The ML lifecycle: experimentation, training and inference
Let’s walk through the ML lifecycle at a high level. Data scientists develop ML systems in the modelling environment. This environment isn’t just a clean room; it’s an instantiation of the full ML lifecycle— experimentation, training and inference.
Once a data scientist has a model they like, they can initiate the training and inference logic in the training environment. That environment’s strict policies allow us to track data lineage and associate the training data and logic with the resulting model.
The role of the training environment is to enable ML models to be trained, registered in the model registry and approved. It allows training jobs to be started manually or programmatically through application triggers or on a schedule. So, you can move from the freedom of the modelling environment to the control of a managed training environment.
Once a model is approved, it becomes eligible for deployment in the inference environment. This environment is used to deploy models from the model registry of the training environment as inference endpoints. The deployment process handles model version upgrades. It can also manage rollbacks in cases where the quality conditions are not met by the new version of the model.
Key features of the Nebula platform
Nebula’s novel approach features:
- A focus on models, not infrastructure. By using trusted industry tools, data scientists can focus on their value-add in building state-of-the-art models.
- Archetype-based development. Like the archetype paradigm of the Apache Maven Project, Nebula allows data scientists to spin up new projects fast that are based on existing templates for full projects or subcomponents. If there are no templates that serve a project’s needs, users may fork templates and promote an enhanced version as a new template.
- Cloud native. Nebula is built on AWS SageMaker. As a result, functionality like autoscaling and blue-green deployments can be delegated to it. Project orchestration is built on serverless services for a fully managed user experience.
- Extensible pipelines. Nebula has consistent infrastructure, which means it can support numerous models.
- Smooth deployment. By optimising for common use cases, we support various latency requirements with templatized deployments.
- Opinionated. To support data scientists’ productivity, we optimise for the common use case and allow for the special use case.
- Tight integration and collaboration. We focus on commonalities across use cases to minimise the total cost of ownership (TCO). Our goal is to optimise at a company level—rather than a model level—so that issues are resolved faster.
- Security and agility. With infrastructure as code and bundled CI/CD logic, we programmatically ensure that security best practices are enforced each time we deploy a model. And by reusing code in multiple places, we reduce Nebula’s attack surface.
To learn more about our approach, you can check out our recent podcast with AWS, Accelerate Machine Learning for SaaS Projects with Proofpoint, which is available on demand.
Now that we’ve covered the high-level flow and key features of Nebula, let’s dive into each of the environments, starting with modelling.
Modelling
Nebula’s modelling component is rich and flexible so that data scientists can experiment and build the right model with speed and ease. Features include:
- Rich templates. We offer quick-start project templates with default patterns for common use cases, validated training pipelines and reasonable defaults for inference configurations.
- Stable infrastructure. The modelling environment’s stable infrastructure allows researchers to ramp up on new projects fast. And once a new model is ready, they can move to production quickly. Supporting access to common data sources out of the box allows new projects to avoid many startup costs. Plus, data scientists can start exploratory data analysis right away.
- Flexibility and segmentation. The modelling environment is built as an isolated data clean room where test models can be deployed. The environment allows for detailed testing and quality assurance and includes security guarantees.
- Model validation. Data scientists should be able to self-validate their work before moving a project to production. For that reason, the modelling environment covers the complete development lifecycle. This lifecycle spans from training to inference components, all of which can be evaluated by data scientists.
Changes committed to feature Git branches trigger automation to build and deploy a model endpoint in the modelling environment. Meanwhile, commits to release branches trigger automation in the model training and inference environments, with production-level deployment guarantees.
Model training
The training phase is simplified and secure with Nebula. The platform provides:
- Automated training. You can just push your code to the main branch, and Nebula manages the rest. Training can start manually or programmatically through application- or time-based triggers.
- Security and monitoring. Protected infrastructure enforces data governance contracts. Dashboards, alarms and metrics support robust observability.
- Data sovereignty. Protecting customer data and privacy is vital. So, the model training environment in Nebula can be isolated in multiple regions to keep the data in place.
- Model registry. The model registry in the training environment offers a single source of truth for model versions and data lineage. Approval status of a model reflects whether or not the model has been vetted for deployment. A simple status change to “Approved” or “Rejected” will result in the model being deployed (or rolled back) in the corresponding inference environment.
Inference
Deploying models for real-time inference is quick and customisable:
- Rapid deployment. After a model is approved in the registry, that model can be deployed to one or more inference environments.
- Versatility. Nebula supports various inference options. That includes out-of-the-box support for AWS SageMaker endpoints. But the platform still allows customisation. Flexible model deployment configurations support different deployment parameters per environment. This flexibility makes it cost-effective.
- Monitoring and scaling. Nebula includes features that help to ensure uptime. The platform also allows us to check model drift and scale as needed.
- Automated shadow deployments. Nebula lets us validate model quality before new versions of models are approved.
- Modularity. Multiple inference environments can deploy models from a single model training environment. That helps to ensure that we deploy the right models in the correct environments with appropriate data controls.
Outcomes
The results of our work with Nebula speak for themselves. Here are the positive outcomes we have seen so far:
- Faster development. Repeatable processes lead to more predictable timelines and costs. And with automated pipelines, we can release changes in minutes.
- Cost efficiency. We can reduce our operational costs through pipeline consolidation and per-environment deployment configurations.
- Rapid training. The Nebula platform can handle massive volumes of data with multiple trainings per day.
- Smooth deployment. Canary launches, staged rollouts and shadow deployments and other Nebula features allow us to catch problems with models before they hit production.
- Empowered teams. By empowering our data scientists and ML engineers to work with models more easily, we can minimise DevOps overhead. We can also maximise customer value.
- Maintainability. As we continue to improve the Nebula platform, we can test our tooling in sandbox or lab environments. We can verify all the functionality before we bring changes to existing and new ML projects.
It’s a snap for us to stamp out new versions of Nebula for rapid experimentation. Through the coupling of infrastructure and projects, Nebula allows for a fluid, interconnected and secure experience for our software engineers, ML engineers and data scientists.
New code contributors can jump in with ease
Proofpoint manages the Nebula platform as an innersource (internal open source) project. All Proofpoint engineers can make pull requests on the Nebula codebase. That way, we can support project needs across the company and make sure that we optimise for common cases while allowing for custom uses.
Nebula’s modular design allows new code contributors to make changes to one component without the need to learn the entire Nebula codebase.
Looking ahead
The world of cybersecurity is always evolving, with threat actors’ tactics growing more sophisticated by the day. With its integrated approach and focus on rapid development and deployment, the Nebula platform from Proofpoint is an invaluable asset in our work to respond to threats. It also helps us to stay one step ahead of them.
Proofpoint is committed to making our ML platform even more effective. By constantly developing new features and collaborating with other ML industry leaders, we can stay at the forefront of cybersecurity innovation. We are committed to providing robust and agile solutions to meet the security challenges of today—and tomorrow.
Join the team
Interested in building leading-edge ML models while fighting cyber crime? Then join the Proofpoint team. At Proofpoint, ML engineers and researchers work together with universities such as Harvey Mudd College, Duke University and Washington State University to develop innovative solutions to complex problems. With incredible data, best-in-breed processes and tooling, and expert teams, Proofpoint is an ideal place to practice machine learning.
Learn more about career opportunities at Proofpoint.
About the authors

Adam Starr leads the ML and artificial intelligence (AI) teams for the Security Products Group at Proofpoint. His team develops many detection systems behind the core email security offerings from Proofpoint: Email Protection, TAP and Threat Response.
Adam brings a unique blend of technical expertise, strategic leadership and an adventurous spirit to the cybersecurity field. His understanding of complex mathematical and computing principles, combined with his hands-on experience in threat detection and prevention, allows Adam to offer unique insight into the cyber landscape. Adam received his Bachelor of Arts in Mathematics from Pomona College and is an MBA candidate at Stanford University.

Alec Lebedev is an engineering architect at Proofpoint in charge of data strategy. He spearheads the development of distributed data, applications and ML platforms, delivering data as a product. He designed a cloud-based data ecosystem that extracts business value and actionable insights from exabytes of data.
Alec’s leadership in these innovative areas, coupled with his hands-on training of engineering and operations teams, illustrates his technical mastery and collaborative expertise.

Christian Joun is a senior software engineer working in areas such as big data, AI/ML and MLOps for the Proofpoint Security Products Group. Initially focused on front-end development, Christian is now focused on infrastructure and backend problems. He holds a computer engineering degree from Virginia Tech with minors in math and computer science.