
Neural network-based “large language models” like BERT, GPT and their successors have revolutionized the field of natural language processing (NLP). While these general-purpose neural networks can be fine-tuned to perform well on domain-specific use cases, the “tokenizer” models they’re built on top of can’t be altered.
In this post, we demonstrate that a tokenizer trained on English text may not appropriately parse text from a different language or machine-generated logs (e.g., malware forensics). Using a custom tokenizer, however, requires training a new neural network instead of fine-tuning an existing language model. In many cases, using a more optimal tokenizer can allow you to use a smaller, more performant neural network and train it on less data for less time.
The Machine Learning Labs team at Proofpoint built a custom language model for malware forensics that serves as the backbone for Camp Disco, our malware clustering engine. Here’s a closer look at what we did, along with some helpful context for this work:
The rise of large language models
Since the introduction of the “Transformer” architecture in 2017, the field of NLP has been taken over by larger and larger neural network “language models” trained on more and more data at higher and higher cost.
BERT is one such model. It’s been trained on over 3 billion words and is used by Google to interpret user searches. GPT-3 is another massive model with 175 billion learnable parameters. It has drawn attention for its ability to create realistic text in various contexts, from academic papers written by GPT-3 to articles advocating for peaceful AI.
These “large language models” (LLMs) have, in turn, spawned a proliferation of LLM-derived models with varying goals: increasing model throughput, decreasing memory complexity, decreasing model size without sacrificing model performance (a process known as “distillation”), and so on.
Hugging Face’s model hub, for example, contains over 8,400 different pre-trained models that can perform text classification (as of July 26, 2022). Notable pre-trained models available through Hugging Face’s model hub include:
- BERT (“bert-base-uncased”), 21 million downloads in July 2022
- DistilBERT (“distilbert-base-uncased”), a smaller distilled version of BERT, 10 million downloads in July 2022
- GPT-2 (“gpt2”), a predecessor of GPT-3, 10 million downloads in July 2022
- DistilGPT2 (“distilgpt2”), a smaller distilled version of GPT-2, 4 million downloads in July 2022
To demonstrate just how ubiquitous these LLMs are, consider the current state of SuperGLUE: a common benchmark used to track NLP progress. SuperGLUE maintains a leaderboard which tracks model results across eight varied NLP tasks including question answering, reading comprehension and word sense disambiguation.
As of this article’s publication, 21 models have outperformed the SuperGLUE baseline model: all 21 are Transformer-based, and all but one have greater than 100 million trainable parameters (including some with more than 100 billion trainable parameters). Additionally, six LLMs have outperformed the human baseline.
As a result, an increasingly common paradigm in modern machine learning is to use an LLM or LLM-derived model (often a distilled version of an LLM) and fine-tune it on a particular task of interest, rather than training an entire model from scratch. This allows practitioners to build off the generalized language knowledge that these models contain, which means the practitioner needs much less labeled data for their task of interest.
By analogy, imagine teaching new choreography (your task) to a professional dancer (the pre-trained model) and a layperson (an untrained model). In both cases, the choreography is new and must be learned. And, given enough time to practice (labeled data), both people may produce dances of equal quality. But the professional dancer will learn the choreography much more quickly because they already have fundamental dance-related knowledge and experience that the layperson is lacking.
So, why on earth would somebody choose to build their own neural network language model from scratch instead of using an LLM-derived model?
A primer on tokenization and vocabularies
Neural networks fundamentally operate on tensors, multidimensional arrays of floating-point numbers. Running a text sequence through a neural network therefore requires first transforming that text sequence into a tensor. This process is typically divided into two stages:
- Tokenization, where the text sequence is converted into a sequence of integers
- Embedding, where each integer is replaced by a vector of floating-point numbers
A trained tokenizer is defined by a vocabulary of “tokens,” an algorithm used to learn the optimal vocabulary based on some corpus of text, and an algorithm used to take new text and divide it up into a sequence of tokens from the vocabulary.
While there are many different tokenization algorithms, the most important factor that defines a tokenizer is how it defines a token. Word-based tokenizers typically separate text on white space and punctuation and add one token to the vocabulary for each word it observes.
For example, the string “How are you” would be represented as the sequence [“How”, “are”, “you”]. In contrast, character-based tokenizers separate every character out into its own token. For example, the string “how are you” would become [“H”, “o”, “w”, “_”, “a”, “r”, “e”, “_”, “y”, “o”, “u”].
|
Sequence |
Word Tokenization |
Character Tokenization |
|
“How are you” |
[How, are, you] |
[H, o, w, _, a, r, e, _, y, o, u] |
|
“I am fine” |
[I, am, fine] |
[I, _, a, m, _, f, i, n, e] |
In contrast to word-based tokenizers, character-based tokenizers lose the semantic meaning of words or word roots and are entirely reliant on the downstream neural network to learn the meaning of different characters in different words. However, character-based tokenizers are supremely versatile—they can represent all sequences with a quite small vocabulary (essentially, the set of symbols on a keyboard).
Word-based tokenizers, on the other hand, are strongly limited by their learned vocabularies. If a word doesn’t exist in the tokenizer’s vocabulary, it gets represented as a special “out of vocab” token, even if it’s highly similar to a known token (e.g., a misspelling or different tense).
Subword tokenizers were recently introduced and aim to achieve the best of both worlds. In subword tokenizers, the vocabulary is comprised of “subwords” of arbitrary length. At their smallest, they can correspond to individual characters, and at their largest, entire words.
Some subword tokenizers also differentiate between tokens at the start of a word and tokens in the interior of word (which are typically prefaced by “##”). There are several different algorithms for learning and applying subword vocabularies, but fundamentally they produce tokenizations that align much more closely with how humans parse words. For example:
“read” -> [read]
“reads” -> [read, ##s]
“reading” -> [read, ##ing]
“reader” -> [read, ##er]
Subword tokenizers therefore have become the de facto standard for deep learning-based language models, including LLMs.
The final step in tokenization is common across all varieties. A simple dictionary lookup replaces individual tokens with unique integer indices (typically corresponding to that token’s location in the tokenizer’s learned vocabulary). This then completes the transformation from a sequence of text characters to a sequence of integers.
Section A of Figure 1 below demonstrates the end-to-end tokenization process given a learned vocabulary (see section B).
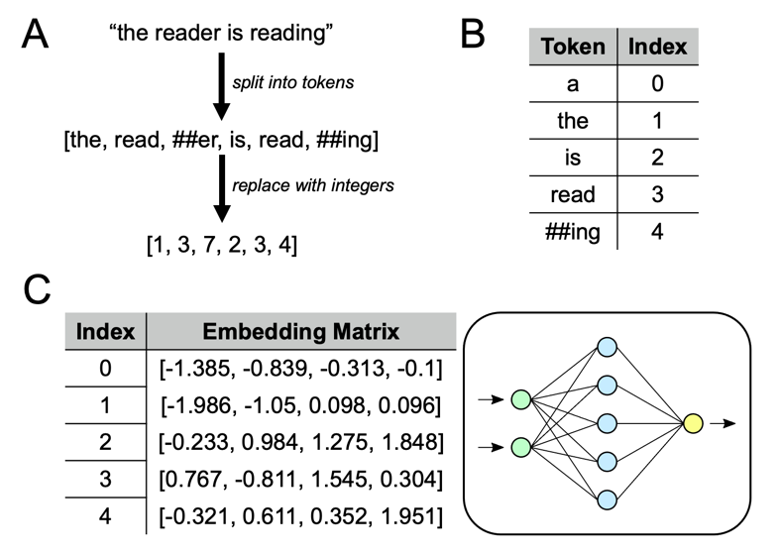
Figure 1. Neural network image courtesy of Wikimedia Commons.
The embedding step is comparatively simple. Each integer is replaced by the corresponding row vector drawn from an “embedding matrix” (see section C in Figure 1 above). This embedding matrix is part of the downstream neural network’s set of learnable parameters and is learned during model training. In the case of LLM-derived models, the pre-trained tokenizer and embedding matrix may be taken from the original LLM, and only the remainder of the neural network is learned anew.
Practically speaking, this means that any given LLM or LLM-derived model has at its foundation a vocabulary (learned by the tokenizer) and an embedding matrix (which has one row vector for each item in the vocabulary). This is one of the principal reasons why an LLM trained only on English text will perform poorly on text in French, German or any other language. The vocabulary learned by the tokenizer (and the associated embedding matrix) is intrinsic to the training data set, and French or German text looks substantially different from English text.
While it’s possible to take a pre-trained tokenizer and embedding matrix and use them as the foundation of a new neural network, the converse is not generally true: By replacing the tokenizer and embedding of a pre-trained LLM with new components, we fundamentally break the LLM.
The language of malware analysis
Malware analysis and detection is largely concerned with static and behavioral forensics. These forensics can take many different forms: URLs, file paths, Windows API function names and more. While many of these forensics may sometimes appear vaguely English-like, they clearly form their own language with very different spelling and grammatical conventions.
What happens when we apply a tokenizer trained on English text to these forensics data? Take, for example, the made-up but plausible URL:
https://login.microsoftonline.foobar.gq/wp-includes/login.php
A human with some relevant domain expertise can easily parse the URL into its constituent elements: protocol, domain, host, TLD and so on. TLDs, in particular, may contain sequences of characters (e.g., “gq”) that are unlikely to appear together in normal English text. In some cases, string segments may be easily decomposed into discrete “words” despite there being no white space or non-alphanumeric characters separating them (e.g., “microsoftonline” -> [“microsoft”, “online”]).
However, having a human manually parse every URL, file path and API call that appears in threat forensics clearly isn’t a scalable process. Instead, we can try to use a tokenizer model to mimic how a human might parse each item.
The tokenizer used in the BERT model was trained on 3.3 billion English words, mainly drawn from English Wikipedia and books. When we apply the BERT tokenizer to our sample URL, we can clearly identify discrepancies between the tokens produced and how a human would parse the URL (see Figure 2, top). In contrast, if we train a custom tokenizer directly on forensics data, we get a tokenizer that parses the URL much more similarly to how a human would parse it (see Figure 2, bottom):
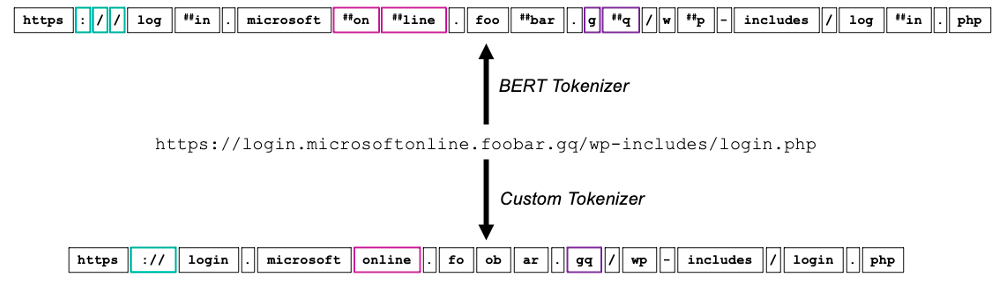
Figure 2. BERT tokenizer vs. custom tokenizer.
As mentioned previously, the tokenizer is the foundation of an LLM, and it’s not practical to replace an LLM’s tokenizer with a custom version while still preserving the knowledge embodied in the LLM.
While it may be possible for a downstream neural network (e.g., BERT) to compensate for suboptimal tokenization, the improvements seen in state-of-the-art performance on various NLP tasks after the introduction of subword tokenizers (relative to the character- and word-based tokenizers used before) suggest that it’s an uphill battle.
Similarly, while it may be possible to leverage a pre-trained LLM by augmenting its tokenizer and embedding matrix with domain-specific tokens, it represents a significant challenge in practice (the details of which are beyond the scope of this article).
In this case, our team at Proofpoint elected to eschew LLMs entirely and train a custom tokenizer and neural network language model. Overall, we were able to use much less data to produce a tokenizer that is both smaller and more effective.
Using a tokenizer that more closely aligns with human behavior is a form of inductive bias, which allowed us to build a smaller neural network and train it on less data without sacrificing model performance. This custom language model for malware forensics forms the backbone of Proofpoint technologies like Camp Disco, a malware clustering engine used by the Proofpoint threat research team to identify patterns in threat data.
By using a language model trained specifically on malware forensics, Camp Disco can identify and surface filenames, URLs and other forensic artifacts associated with clusters of related threats, enabling quicker identification and correlation of both advanced and commodity threats to customers.
What’s right for me?
Since the introduction of BERT and GPT, NLP has been undergoing its own “ImageNet moment.” Large language models (and LLM-derived models), many of which have open-source implementations freely available, are taking the field by storm, making it easier and easier for machine learning practitioners to address their own NLP problems with unprecedented performance. However, even the largest and most powerful of these models are fundamentally “locked into” the set of languages that the model and its tokenizer were trained on.
In this article, we addressed the case of applying NLP techniques to malware forensics and demonstrated that a custom-trained tokenizer will parse input data in a much more intuitive and expert-like way than the tokenizer used by BERT. While LLMs may have the flexibility and complexity to learn well even with suboptimal tokenization, using a custom tokenizer can help you achieve high levels of task performance with a smaller model and less training data.
Join the team
At Proofpoint, our people—and the diversity of their lived experiences and backgrounds—are the driving force behind our success. We have a passion for protecting people, data and brands from today’s advanced threats and compliance risks.
We hire the best people in the business to:
- Build and enhance our proven security platform
- Blend innovation and speed in a constantly evolving cloud architecture
- Analyze new threats and offer deep insight through data-driven intelligence
- Collaborate with our customers to help solve their toughest cybersecurity challenges
If you’re interested in learning more about career opportunities at Proofpoint, visit this page.
About the authors
Zachary Abzug is currently a data science and engineering manager on the Machine Learning Labs team at Proofpoint. At Proofpoint, he has worked on various projects at the intersection of machine learning, phish and malware detection, and threat research and intelligence. He holds a Ph.D. in neuroengineering from Duke University. Zack enjoys cooking, reading fiction, playing soccer, and coming up with highly contrived and amusing project names (e.g., Camp Disco).

Cole Juracek is a data scientist on the Machine Learning Labs team at Proofpoint. He graduated from Duke University in 2021 with a master’s degree in statistical science and is a former Proofpoint intern. In his free time, Cole enjoys running and playing Dance Revolution.
