
Les entreprises ont de plus en plus de mal à protéger les informations stratégiques, telles que la propriété intellectuelle et les secrets commerciaux. En effet, les anciens systèmes de sécurité des données étaient principalement conçus pour identifier et protéger des types de données structurées, telles que les données personnelles, les données médicales personnelles et les données de paiement. Ces systèmes sont peu performants pour comprendre les données non structurées, en particulier les documents, car ils se concentrent sur des éléments de données discrets plutôt que sur le contexte plus large ou le but de l'information. Ils ont du mal à identifier les documents métier sensibles, à moins que ces documents ne correspondent à des modèles prédéfinis.
Les classificateurs pilotés par l'IA changent la donne. Ces classificateurs utilisent de grands modèles de langage (LLM) entraînés avec de vastes ensembles de documents d'entreprise. Grâce à cet entraînement, ils apprennent à reconnaître des types de documents nuancés, tels que les secrets commerciaux, les formulaires médicaux, les documents de conformité et les accords juridiques. Les classificateurs pilotés par l'IA vont au-delà des simples mots-clés. Ils utilisent le contexte et la compréhension sémantique pour catégoriser les documents selon la fonction métier et l'intention. Lorsqu'ils sont entraînés davantage avec les données d'une entreprise, ces classificateurs à apprentissage automatique s'adaptent au langage, à la structure et aux workflows uniques de l'entreprise. Ils développent continuellement leur capacité à identifier où résident les informations critiques et comment elles se déplacent. Cela permet aux entreprises d'adopter des stratégies de protection des données plus précises et proactives.
En quoi consistent les classificateurs pré-entraînés ?
Les classificateurs pré-entraînés de Proofpoint offrent un moyen efficace d'identifier et de protéger les documents stratégiques. Ces derniers incluent le code source, les documents comptables et fiscaux, les dossiers des collaborateurs, les accords et les contrats. Nos classificateurs pilotés par l'IA sont alimentés par des LLM qui catégorisent les documents en temps réel. En combinant des modèles d'IA open source avec des algorithmes propriétaires et un processus qui vous permet de valider les résultats, Proofpoint peut identifier l'objectif d'un document et le catégoriser avec une confiance de 85 % ou plus.
Vous pouvez utiliser des classificateurs LLM pré-entraînés dans des règles DLP pour protéger le contenu nouveau ou négligé précédemment, sans avoir besoin d'une classification préalable. Cela permet de gagner du temps et de réduire les efforts déployés. En combinaison avec la correspondance de modèles, les classificateurs LLM aident également à réduire les faux positifs. Par exemple, avec Proofpoint Enterprise DLP, vous pouvez permettre à votre équipe RH de partager des documents sensibles en interne, tout en supprimant automatiquement les autorisations si ces documents sont partagés en dehors de l'équipe.
Les alertes enrichies par des LLM permettent également aux analystes de trier et d'enquêter sur les incidents plus rapidement. Par exemple, si une alerte est déclenchée par une correspondance de modèle de numéro de sécurité sociale, Proofpoint Enterprise DLP peut identifier si le document concerne l'impôt sur le revenu, un formulaire de patient ou une demande de crédit.
Cependant, les classificateurs LLM pré-entraînés peuvent avoir des limites. Comme ils reposent sur des données d'entreprise statiques et des étiquettes fixes, ils ne s'adaptent pas bien aux menaces en constante évolution, aux contextes métier changeants ou aux finalités des documents. Ils peuvent manquer des signaux subtils, entraînant une mauvaise classification ou des faux positifs. C'est pourquoi les classificateurs à apprentissage automatique deviennent essentiels.
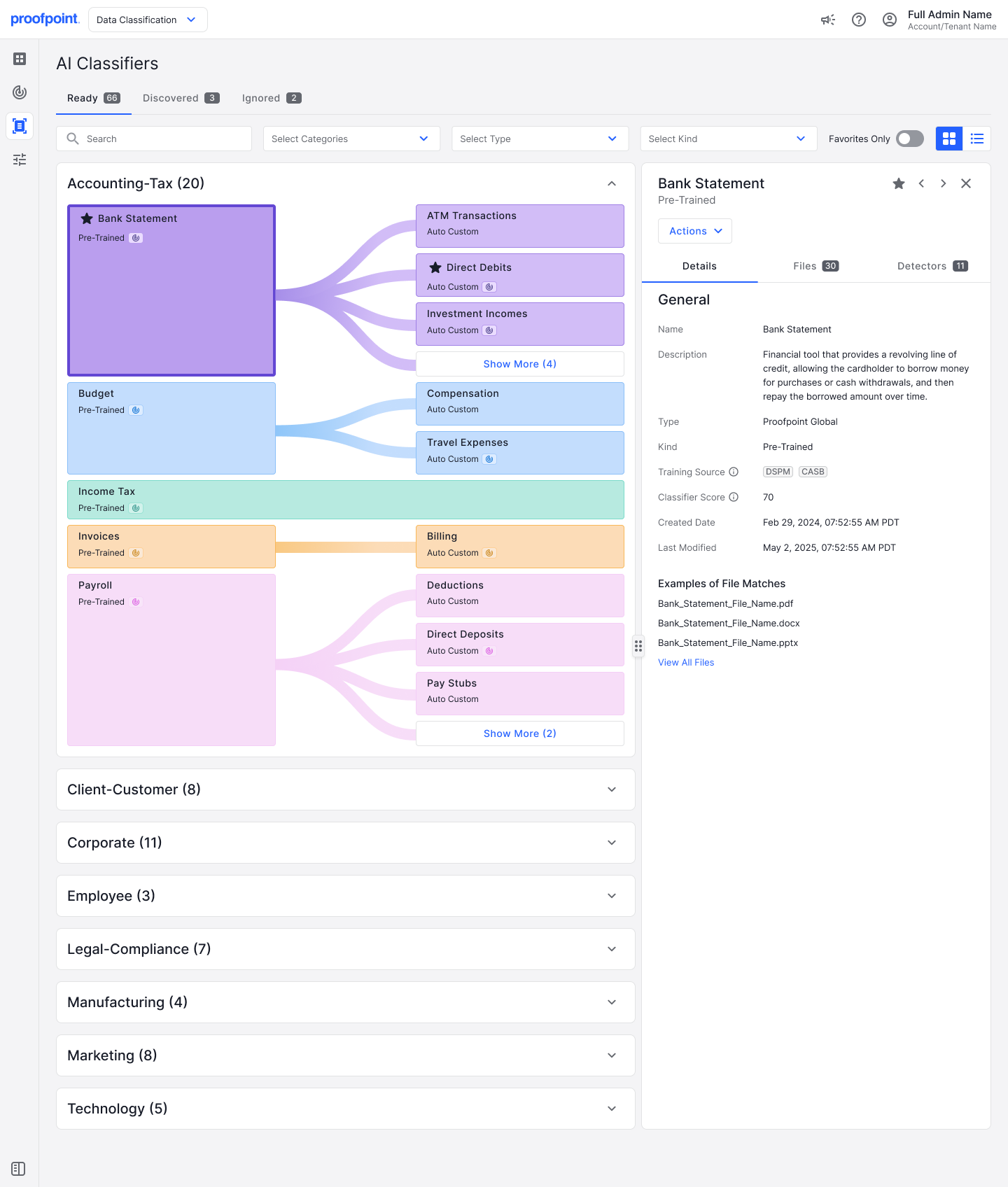
Figure 1. Classificateur d'IA pré-entraîné pour un relevé bancaire dans la catégorie de documents « Accounting-Tax » (Comptabilité/Fiscalité).
En quoi consistent les classificateurs à apprentissage automatique ?
Les classificateurs à apprentissage automatique de Proofpoint sont conçus pour identifier les informations nouvelles ou propres à votre entreprise. Ils s'adaptent en permanence en observant les interactions en temps réel, les schémas d'accès et le contexte comportemental. Cela se traduit par une classification des données plus précise, dynamique et résiliente, avec un minimum d'intervention humaine.
En s'appuyant sur des classificateurs LLM pré-entraînés, les classificateurs à apprentissage automatique affinent dynamiquement leurs propres modèles en observant les modèles de données cachés d'une entreprise. En utilisant l'IA générative, ils peuvent prédire et nommer automatiquement de nouvelles catégories de données et de documents, comme de nouveaux formats de données personnelles ou de nouveaux articles de recherche.
Cette approche alimentée par l'IA permet à notre solution de sécurité des données d'améliorer continuellement la précision de la classification en fonction du contexte des données en direct, ce qui réduit les faux positifs et les lacunes en matière de couverture. Et parce qu'elle s'intègre parfaitement à Proofpoint Enterprise DLP et à Proofpoint Data Security Posture Management, elle ne se contente pas de classer le contenu sensible, mais applique également des protections adaptatives en temps réel. Ces protections incluent la révocation des privilèges d'accès excessifs ou le signalement des catégories de documents ou de données à haut risque. Vous obtenez ainsi une défense entièrement automatisée et évolutive contre l'exfiltration et l'exposition de données.
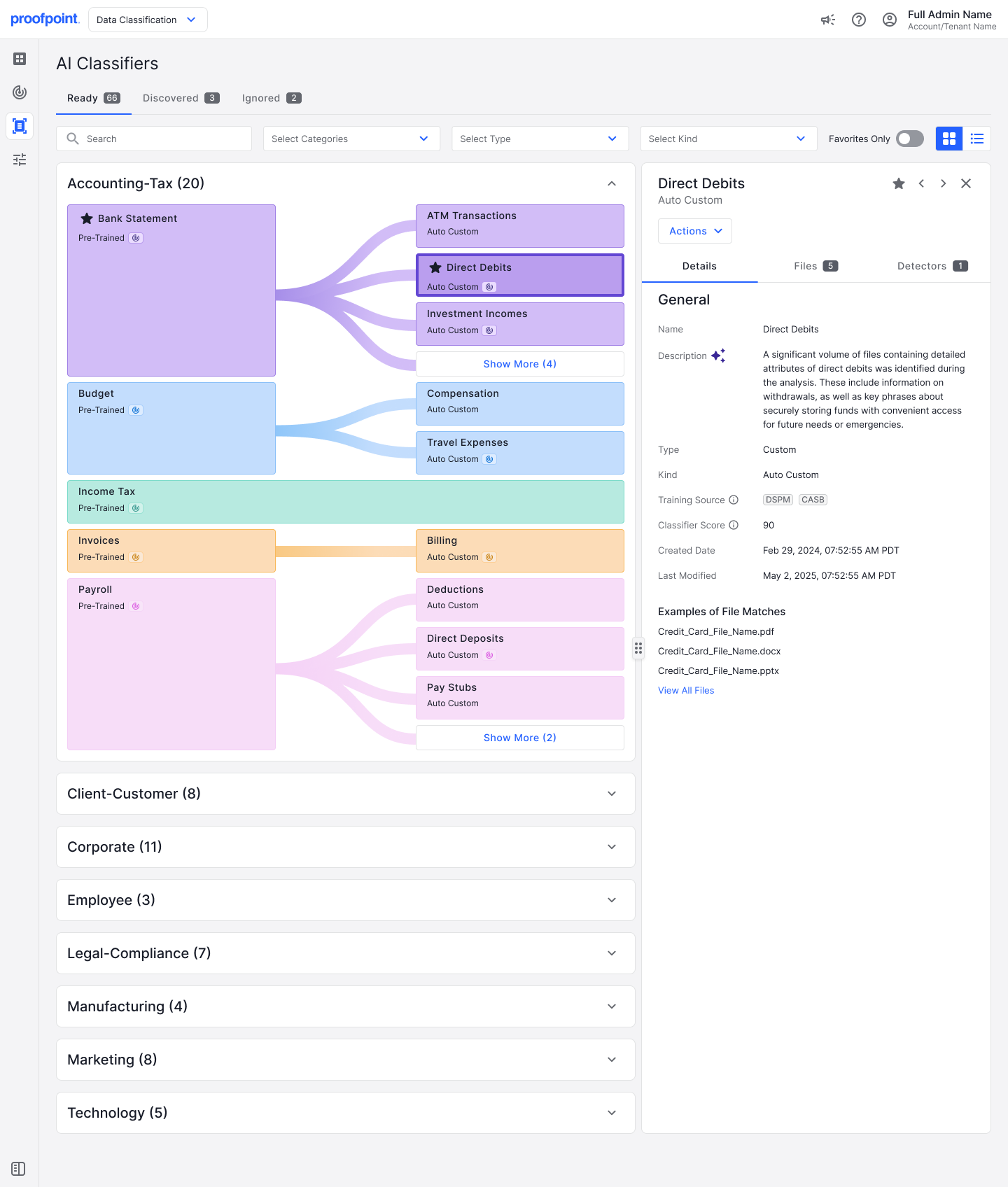 Figure 2. Classificateur IA à apprentissage et nommage automatique pour les prélèvements automatiques, une sous-catégorie de la catégorie « Bank Statement » (Relevé bancaire).
Figure 2. Classificateur IA à apprentissage et nommage automatique pour les prélèvements automatiques, une sous-catégorie de la catégorie « Bank Statement » (Relevé bancaire).
Comment les classificateurs à apprentissage automatique vous aident-ils à trouver le juste équilibre entre innovation et confidentialité ?
Les classificateurs à apprentissage automatique tirent des enseignements de modèles comportementaux et de signaux contextuels sans exposer de contenu sensible. En ne partageant que des informations anonymisées ou agrégées, ils réduisent les risques de confidentialité tout en améliorant la précision de la classification. Cette approche offre une protection des données adaptative qui ne compromet ni la confidentialité ni la conformité réglementaire.
Comment l'approche unifiée de sécurité des données pilotée par l'IA de Proofpoint peut-elle vous aider ?
La classification des données et des documents pilotée par l'IA est la première étape essentielle vers une sécurité et une conformité des données plus intelligentes et basées sur des agents. Elle fonctionne comme le système sensoriel de votre entreprise, en permettant aux agents de sécurité automatisés (le système nerveux) de voir, de comprendre et de répondre aux risques. En donnant un sens aux données, ces classificateurs permettent aux agents de sécurité d'agir avec intelligence et précision.
Sans une classification précise, les agents d'IA ne disposent pas du contexte nécessaire pour appliquer des règles, détecter des anomalies ou répondre aux menaces. Les classificateurs pilotés par l'IA résolvent ce problème en identifiant les informations sensibles — telles que les données personnelles, les données médicales personnelles, les données de paiement, le code source et les documents nouveaux ou propres à votre entreprise — dans les applications cloud, les endpoints, les emails et les espaces de stockage. Ils permettent une catégorisation et un étiquetage en temps réel. Cela oriente les actions en aval, telles que le blocage des transferts de fichiers à risque, la révocation des accès, l'escalade des incidents internes ou l'application du chiffrement.
À mesure que les environnements deviennent plus complexes et dynamiques, la classification alimentée par l'IA peut évoluer pour gérer des pétaoctets de données et des millions de fichiers et de messages. Elle peut fournir des informations continues aux systèmes de sécurité agentiques. À leur tour, les agents d'IA peuvent ajuster les règles et les réponses en fonction de la confiance, de la gravité et de la mise en correspondance réglementaire de la classification. Cela contribue à garantir la conformité à des cadres tels que le règlement général sur la protection des données (RGPD), la loi HIPAA (Health Insurance Portability and Accountability Act) et le CCPA (California Consumer Privacy Act), sans reconfiguration manuelle constante.
Tout comme le corps ne peut pas réagir au danger sans stimuli sensoriels, la sécurité autonome des données ne peut pas fonctionner sans comprendre quelles données et quels documents elle protège. La classification optimisée par l'IA offre la vision et la sensibilisation qui permettent aux agents de sécurité et de conformité d'agir rapidement, avec précision et à grande échelle.
En savoir plus
Pour en savoir plus sur nos classificateurs pilotés par l'IA et les solutions Proofpoint de sécurité des données, regardez le webinaire Defend Data Innovations.