
« Perspectives d'ingénierie » est une série d'articles de blog offrant un aperçu des coulisses des défis techniques, des enseignements et des avancées qui aident nos clients à protéger leurs collaborateurs et leurs données au quotidien. Dans les articles qu'ils rédigent, nos ingénieurs expliquent le processus qui a conduit à une innovation Proofpoint.
Les entreprises font face à un flux incessant de menaces liées à des activités internes, d'où l'importance d'identifier les cas dans lesquels les comportements des utilisateurs s'écartent des schémas habituels. Il est également primordial de prévenir la fuite de données sensibles.
Chez Proofpoint, nous avons conçu un pipeline sophistiqué de détection des anomalies. En plus de modéliser le profil comportemental de chaque utilisateur, ce pipeline agrège des informations propres aux locataires. La précision de la détection et la prévention des menaces s'en trouvent ainsi améliorées.
La détection des comportements anormaux dans un système multilocataire s'accompagne de défis uniques. Nous devons préserver l'isolation des données tout en assurant l'évolutivité. Le modèle doit également gérer la dispersion des données et effectuer une ingénierie complexe des caractéristiques pour garantir la prise en compte des activités utilisateurs les plus significatives sur le plan statistique.
Pour travailler efficacement à grande échelle, nous utilisons des endpoints multimodèles. Voici comment.
Profilage du comportement des utilisateurs
Pour détecter les activités anormales, nous commençons par établir des profils complets du comportement des utilisateurs. Chaque profil capture des schémas comportementaux distincts pour les utilisateurs individuels du locataire. Nous répétons l'opération pour chaque locataire de façon totalement indépendante, en respectant des règles strictes de conformité des données.
Ce profil comprend des indicateurs statistiques clés, tels que l'écart type modifié, les valeurs de centile et d'autres indicateurs dérivés, ce qui nous permet de caractériser efficacement la distribution des activités d'un utilisateur sur une période de plusieurs jours.
Nous avons déterminé que les activités des utilisateurs à variance minimale constituent souvent les indicateurs les plus critiques d'un comportement anormal. En priorisant les caractéristiques à faible variance, il est possible d'identifier les signaux comportementaux les plus pertinents et, ce faisant, d'améliorer la résistance du modèle au bruit.
L'approche de modélisation traditionnelle recommande de laisser tomber les caractéristiques à faible variance, car celles-ci peuvent être moins informatives et plus sujettes au bruit. Toutefois, pour la modélisation des comportements liés aux activités, les caractéristiques à faible variance peuvent offrir un schéma comportemental normal qui peut s'avérer utile pour l'identification des clusters de groupes d'homologues. Les légères variations ne doivent pas être assimilées à du bruit et ignorées. Par exemple, un proxy VPN servant aux utilisateurs d'un bureau déterminé peut être défini comme une faible variance, mais un changement d'adresse IP d'accès peut indiquer une anomalie.
Isolation des données
La sécurité et la confidentialité des données étaient des considérations essentielles étant donné qu'il s'agit d'un système multilocataire. Nous avons mis en place une séparation stricte des données afin de prévenir toute fuite d'informations entre locataires. Le profil de chaque utilisateur est établi à partir de données appartenant au locataire de cet utilisateur. Par ailleurs, chaque locataire dispose de son propre modèle d'apprentissage automatique (ML). Cette conception garantit une isolation robuste des données.
Profils locataires
Nous avons également établi des profils locataires qui caractérisent les schémas comportementaux globaux au sein de l'environnement du client. Les profils locataires identifient des indicateurs clés tels que les schémas d'utilisation des sites Web, les tendances en matière d'activités et d'autres attributs à l'échelle du locataire. Nous avons ensuite combiné les profils des utilisateurs et les schémas plus généraux du locataire concerné, puis avons amélioré la capacité du système à distinguer les écarts légitimes des faux positifs.
Inférence
Notre pipeline d'inférence évalue l'activité d'un utilisateur sur une période définie. Le profil comportemental de l'utilisateur et le profil locataire correspondant sont utilisés afin de calculer un score dynamique d'anomalie de l'activité de l'utilisateur.
Les activités qui s'écartent considérablement des schémas habituels sont signalées comme étant des anomalies. Les événements anormaux sont alors signalés et ajoutés au modèle de données avec une explication visible dans l'interface utilisateur, comme illustré sur la figure 1 ci-dessous.
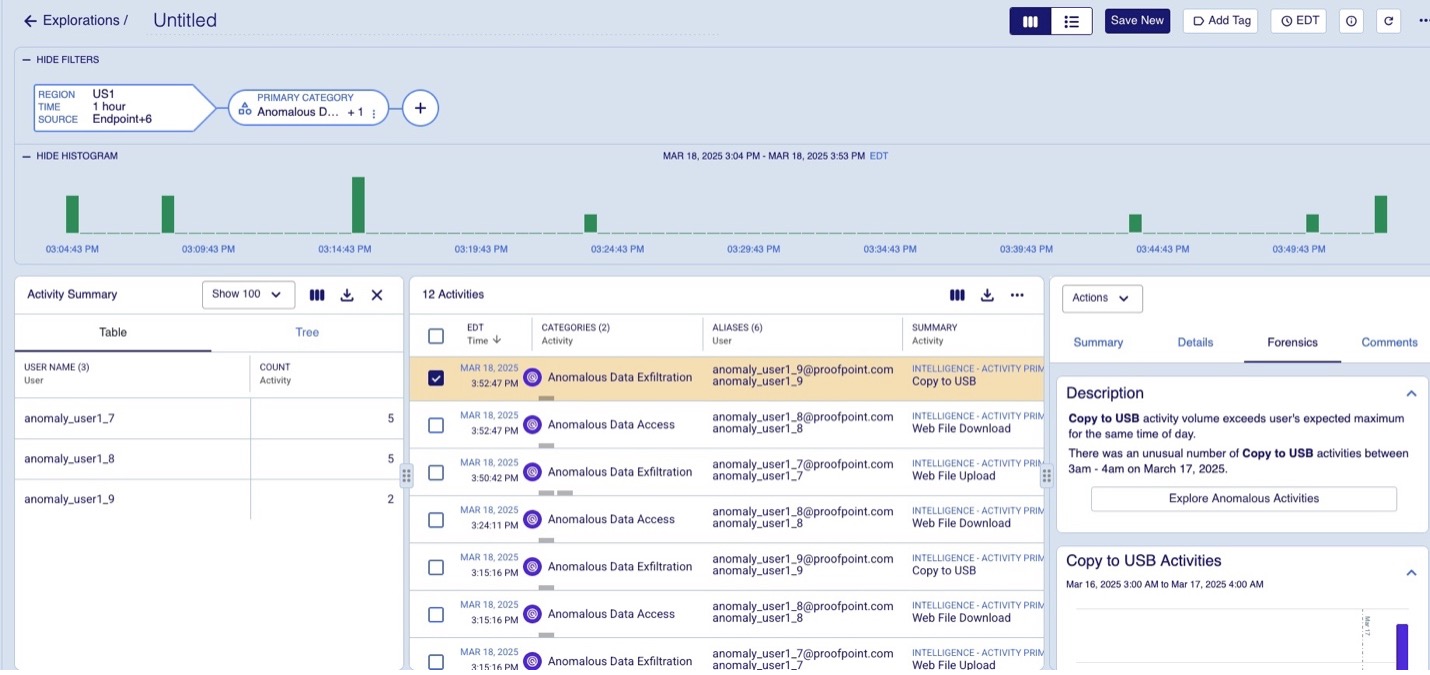
Figure 1. Activités anormales signalées
Pour faire évoluer efficacement le système, nous avons utilisé des endpoints multimodèles. Notre pipeline d'inférence est illustré sur la figure 2.
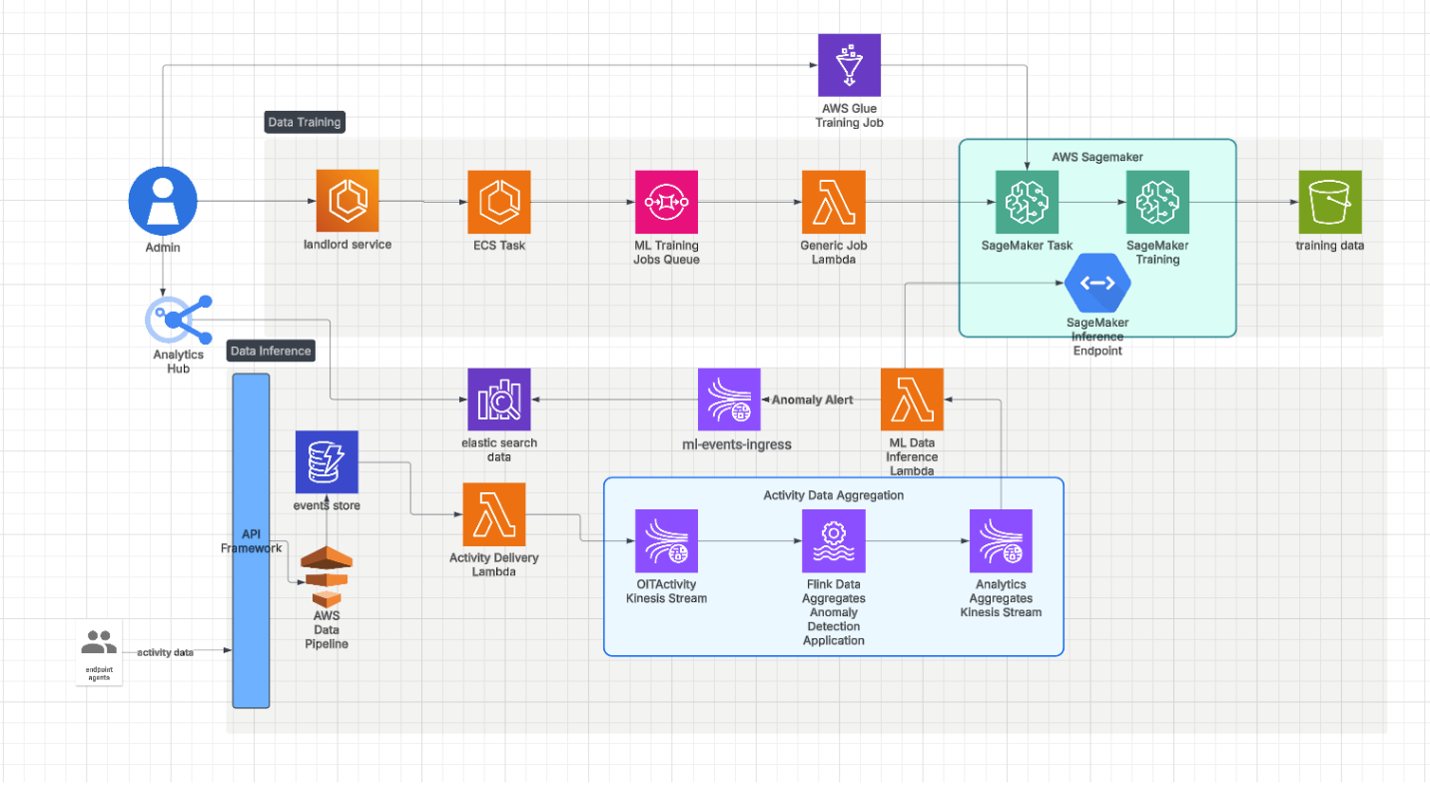
Figure 2. Architecture du pipeline
Les endpoints multimodèles permettent d'héberger plusieurs modèles sur un même endpoint, pour un chargement et un déchargement dynamiques et à la demande des modèles. Cette approche réduit considérablement les coûts d'infrastructure, car elle permet d'optimiser l'utilisation des ressources.
D'après nos tests, elle a également assuré une faible latence pour le cycle d'inférence en temps réel. Chaque modèle d'apprentissage automatique (ML) est stocké dans un blob, ou grand objet binaire, et chargé dynamiquement selon les besoins, ce qui permet de changer rapidement et efficacement de modèle. Les endpoints multimodèles nous ont permis de gérer plusieurs modèles sous un même endpoint, rationalisant ainsi notre stratégie de déploiement. Nous avons ainsi pu évoluer facilement à mesure de l'augmentation du nombre de locataires.
Travaux futurs
À l'avenir, nous prévoyons d'utiliser de grands modèles de langage (LLM) et des workflows d'IA agentique pour renforcer notre pipeline de détection des anomalies. Les grands modèles de langage (LLM) pourraient résumer les activités sur une période définie, en extrayant automatiquement les informations clés et les anomalies. Les analystes en sécurité bénéficieraient alors d'informations plus exploitables et la prise de décisions serait plus rapide et plus précise. Par ailleurs, les agents d'IA peuvent se baser sur les détections d'anomalies initiales pour exécuter des workflows, tels que la compilation des résultats de l'analyse en temps réel du contenu des fichiers et des informations de traçabilité des données, pour éliminer les faux positifs.
Rejoignez l'équipe Proofpoint
Nos collaborateurs, et la diversité de leurs expériences et parcours, sont l'élément moteur de notre réussite. Nous nous sommes donné pour mission de protéger les personnes, les données et les marques contre les menaces avancées actuelles et les risques de non-conformité.
Nous recrutons les meilleurs talents pour :
- Développer et améliorer notre plate-forme de sécurité éprouvée
- Allier innovation et vitesse au sein d'une architecture cloud en constante évolution
- Analyser les nouvelles menaces et fournir des informations détaillées grâce à une threat intelligence axée sur les données
- Collaborer avec nos clients pour résoudre leurs défis de cybersécurité les plus complexes
Si vous souhaitez en savoir plus sur les possibilités de carrière chez Proofpoint, consultez notre page dédiée.
À propos des auteurs

Ram Kulathumani est Senior Manager chez Proofpoint. Il dirige la recherche et le développement sur l'apprentissage automatique (ML) pour des cas d'utilisation critiques relatifs à la sécurité. Récemment, il s'est concentré sur le perfectionnement de grands modèles transformers, la conception de requêtes, l'évaluation de grands modèles de langage (LLM) et l'optimisation des performances d'inférence de l'apprentissage automatique (ML).

Azeem Yousaf est Senior Engineer chez Proofpoint, spécialisé dans le développement de solutions de threat intelligence basées sur l'IA. Son expertise couvre aussi bien le développement d'algorithmes de base que l'ingénierie avancée des caractéristiques. En dehors du travail, Azeem Yousaf aime jouer au cricket dans son club local.

Khurram Ghafoor est Senior Director chez Proofpoint et est spécialisé dans l'architecture de plates-formes de données et les pipelines d'IA/d'apprentissage automatique (ML). Ses 20 ans d'expérience ont fait de lui un expert en développement de logiciels, en conception d'architectures évolutives et en application des technologies d'IA et d'apprentissage automatique.