 uk:
English: Europe, Middle East, Africa
uk:
English: Europe, Middle East, Africa










“A good human plus a machine is the best combination.”
— Gary Kasparov, chess grandmaster and former world chess champion
Many organisations rely on manual processes to identify, classify, secure and protect the data in their custody. However, with data volumes swelling, these processes are no longer viable. Proofpoint Intelligent Classification and Protection (PCIP) can help organisations modernise and enhance their data security. The solution uses advanced artificial intelligence (AI)-based technologies to help solve the problem of modern data security management.
The Intelligent Classification and Protection solution’s AI technologies offer state-of-the-art security at a fraction of the cost of other solutions or manual approaches. In fact, for each hour worked, the solution’s AI-powered classification models can analyse as many documents as a human could in 10,000 hours—with a level of accuracy that’s three times higher than the average human.
While AI is an automated entity that operates independently once trained, it’s essential to involve humans in the AI learning loop. Proofpoint Intelligent Classification and Protection features a classification review module based on “active learning” (the AI learns from human feedback). Involving users throughout the AI model’s life cycle helps ensure the highest model performance as well as the “explainability” of outputs (humans can understand the AI model’s decisions and predictions).
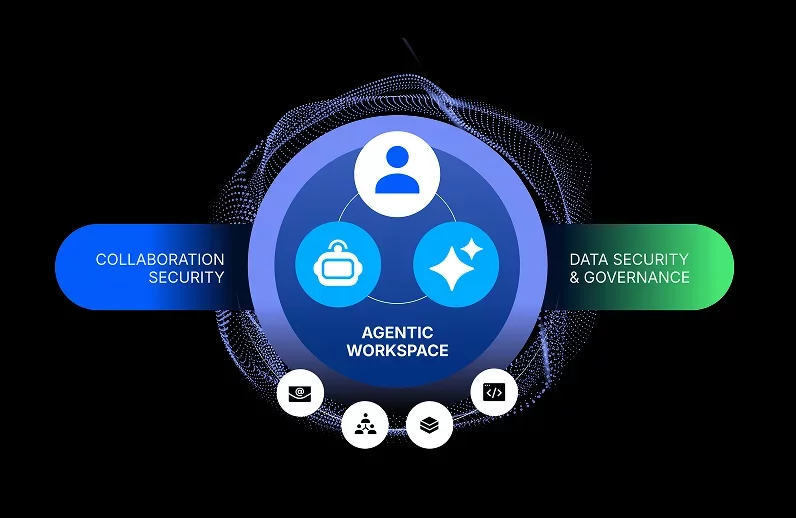
What is classification review?
Classification review is a process where PICP users validate the results of the Proofpoint Intelligent Classification and Protection solution’s mechanism and correct wrong predictions. This process helps ensure better quality. You can also tailor the solution to your organisation by aligning with the data classification policies and adapting the classification dimensions to your internal taxonomy.
Classification review aims to sample a few documents classified through Intelligent Classification and Protection to either validate or correct the AI model’s prediction and provide you with accurate performance metrics. This process ultimately leads to a more accurate model, as these reviews are used for retraining.
What is the classification review workflow?
The classification review workflow includes four key steps:
-
Once your data is classified, Proofpoint Intelligent Classification and Protection uses active learning to sample the most significant set of documents—those with the highest potential impact on the classification model’s quality.
- The Intelligent Classification and Protection solution identifies key users based on their access to the relevant documents selected with active learning. These users are usually a small set of high-risk users with access to recent business-critical data (around 10 to 15 reviewers per campaign).
- Key Users then receive the relevant documents to be reviewed, and either validate the solution’s predictions or corrects them. (Note that it takes, on average, two to three minutes to review a document.)
- Finally, the Proofpoint Intelligent Classification and Protection solution’s classification model retrains itself by using the new information to yield optimal results for the next iteration of classification.
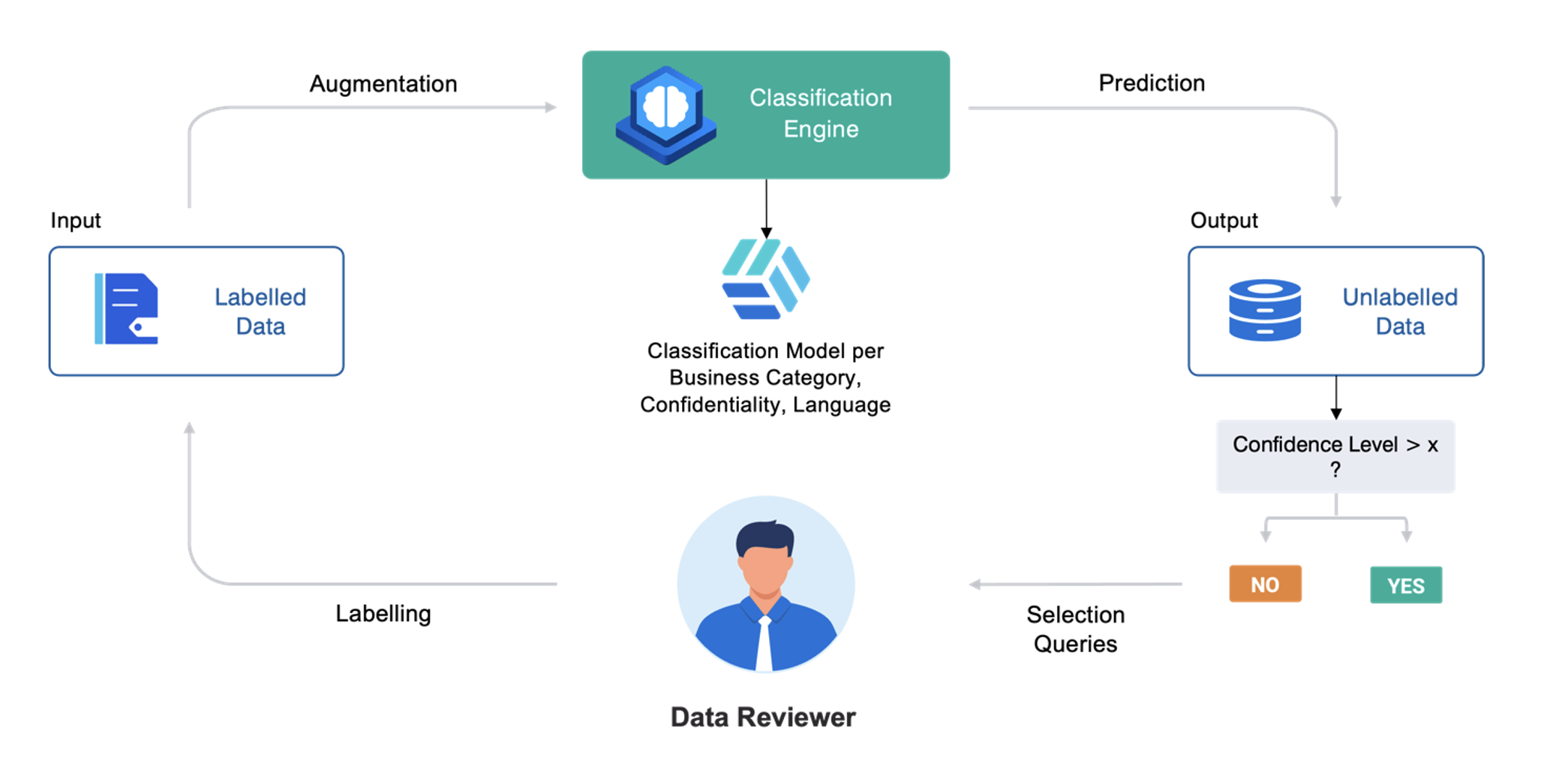
Figure 1. Overview of the classification engine’s review workflow.
The classification review process
At Proofpoint, we understand that a company’s most valuable commodity is time. That’s why we strive to provide a streamlined review module that can be integrated easily with your processes.
Our team helps you set up this exercise by defining information that is most useful for customising the classification review workflow. The process includes three key steps:
- Step 1 is defining the expected improvement in accuracy after the classification review. Reviewing more documents ensures better performance, but it requires more time. Reviewing fewer documents is faster, but it doesn’t provide as significant of a performance improvement.
- Step 2 is defining which departments should take part in the review exercise. You can either choose to involve one (or a few) departments in this process or organise a company-wide classification review campaign with all your departments.
- Step 3 is to define which folders and data sources should be targeted by user review to focus on business-critical data.
As this process is iterative, data sources and departments can be involved one after the other to keep the classification review exercise smooth and simple.
To learn more about the process details and get an overview of the interface, refer to our white paper about classification review.
Expected results
Retraining classification models after a classification review leads to a significant increase in performance, increasing the accuracy by up to 15%. Below are real examples showcasing the performance increase after model retraining:
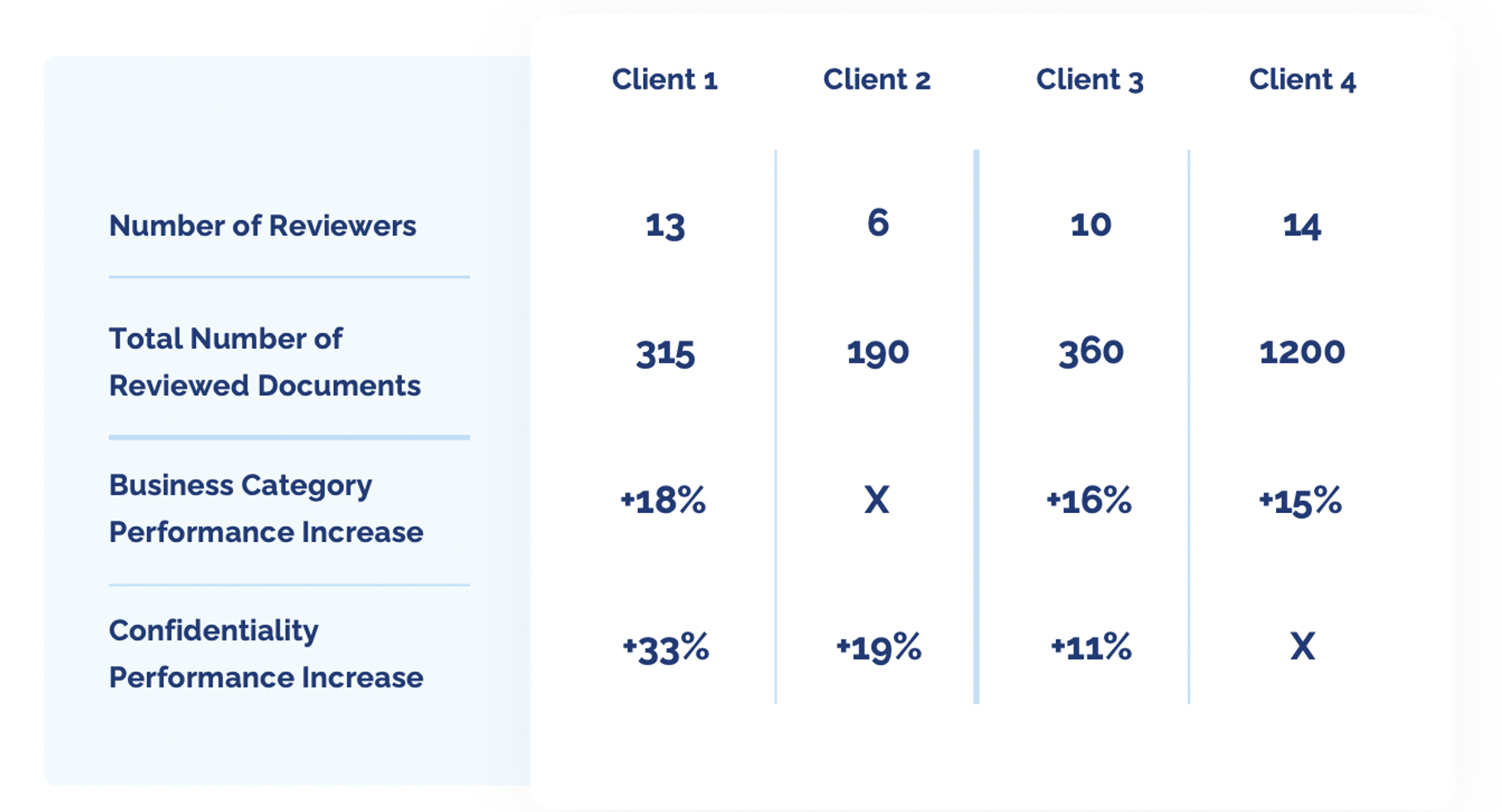
Figure 2. Retraining classification models after classification review.
The technology behind classification review
As mentioned earlier, Proofpoint Intelligent Classification and Protection uses active learning to determine the most relevant documents to review. The following sections give you a peek behind the curtain of how our solution leverages active learning, along with more detail about active learning itself.
What is active learning?
Research scientist Burr Settles defines active learning as “a subfield of machine learning and, more generally, artificial intelligence. The key hypothesis is that if the learning algorithm is allowed to choose the data from which it learns … it will perform better with less training.”
In short, active learning is a sample selection approach that minimises the annotation cost while maximising the performance of AI-based models by only selecting data that the system considers to be the most informative.
How does active learning select relevant documents?
When an AI model makes a prediction, it computes the probability of the document it classifies to belong to a specific category. For example, if we aim to classify an email (defined as a document for the sake of this example) as either spam or non-spam, the output of the model would look like: doc_1 = [0.05, 0.95]. In this case, it is easy to see that the email is very unlikely to be a spam as the probability is only 5%.
However, what happens when the output of the model looks like this: doc_2= [0.49, 0.51]? The AI model would still predict that the email is not a spam, but we can see that the model is clearly confused as it still has a 49% chance of being a spam.
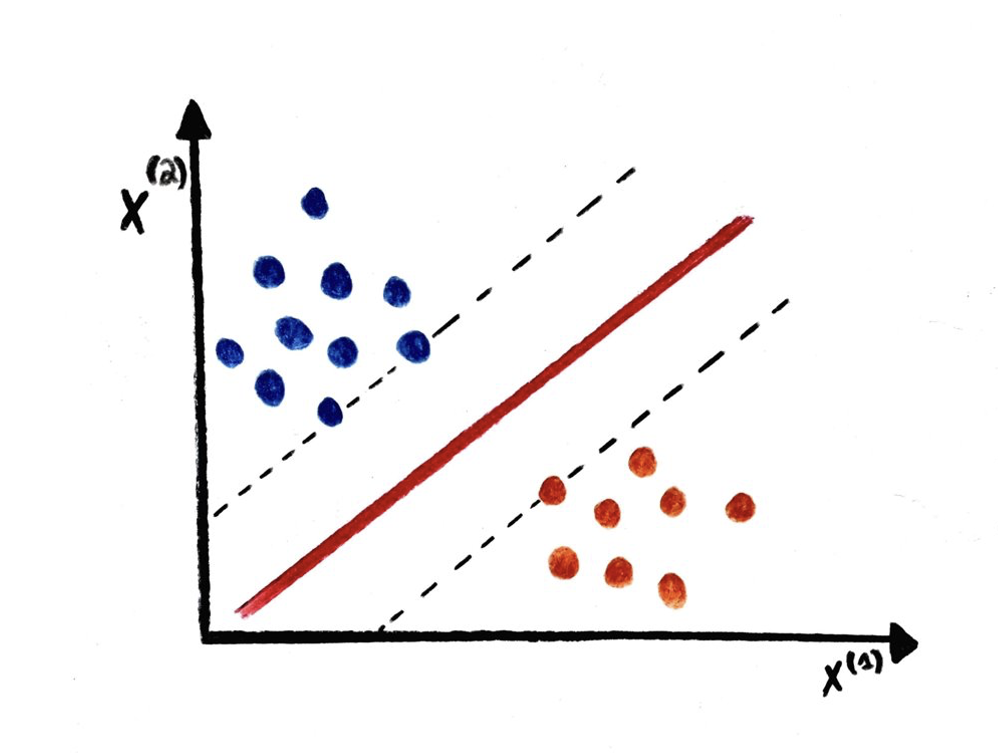
Figure 3. Example of confidence level shown on an X and Y axis.
Active learning uses this information (classification probability) to determine which documents it does not know how to classify properly and would require human review. Intuitively, we see that reviewing doc_1 will not provide the model with much more information, whereas reviewing doc_2 is vital to improving accuracy and making sure no email is missed by the spam detector.
How does Proofpoint Intelligent Classification and Protection use active learning?
To choose the most significant documents to review, the Intelligent Classification and Protection solution for Proofpoint uses two core principles of active learning:
-
Uncertainty: By selecting the documents which the model is most uncertain about, the performance will improve much more than by selecting random documents.
- Diversity: Only selecting similar documents will not be helpful, as it will only give the machine learning model one type of information. Thus, Intelligent Classification and Protection aims to build the most diverse set of documents possible for classification review.
In parallel with these two principles, Proofpoint Intelligent Classification and Protection provides an access-based assignment of documents with recommendations of key users to involve in the process. Reviewers only receive documents they’ve been granted access to across the organisation, instead of documents from a particular category or department they might not know.
Classification review: 3 main objectives
Through its classification review module, the Proofpoint Intelligent Classification and Protection solution uses active learning to allow data owners and key users to validate the results of its classification on the most relevant data. More specifically, classification review aims to:
- Validate the accuracy of the Intelligent Classification and Protection solution’s classification module.
- Improve the performance of our classifiers by correcting wrong predictions.
- Align the predictions from Proofpoint Intelligent Classification and Protection with internal policies and taxonomy by updating the assigned business category and/or confidentiality to fit your expectations.
Classification review offers unprecedented performance, as it allows you to improve the quality of the classification mechanism over time as it evolves to better understand your data.
Join the team
At Proofpoint, our people—and the diversity of their lived experiences and backgrounds—are the driving force behind our success. We have a passion for protecting people, data and brands from today’s advanced threats and compliance risks.
We hire the best people in the business to:
- Build and enhance our proven security platform
- Blend innovation and speed in a constantly evolving cloud architecture
- Analyse new threats and offer deep insight through data-driven intelligence
- Collaborate with our customers to help solve their toughest cybersecurity challenges
If you’re interested in learning more about career opportunities at Proofpoint, visit this page.
About the author
Othman Benchekroun is currently working as a Technical Project Manager at Proofpoint, enabling cross-team collaboration. He has a background in AI and Machine Learning, holding a Data Science MSc from the Federal Polytechnic School of Lausanne, Switzerland. He is passionate about AI evangelisation, making Machine Learning accessible to all and working on PICP’s patenting efforts.
