
Organizations are increasingly struggling to protect business-critical information such as intellectual property (IP) and trade secrets. This is because legacy data security systems were designed primarily to identify and protect structured data types, such as PII, PHI, and PCI. Those systems are poor at understanding unstructured data—especially documents—because they focus on discrete data elements rather than the broader context or purpose of the information. Critically, they struggle to identify sensitive business documents unless those documents match predefined patterns.
AI-powered classifiers are changing this. These classifiers use large language models (LLMs) trained on large datasets of enterprise documents. With this training, they learn to recognize nuanced document types, such as trade secrets, medical forms, compliance documents, and legal agreements. AI-driven classifiers go beyond just keywords. Instead, they use context and semantic understanding to categorize documents based on business function and intent. When they’re further trained on an organization’s data, these autonomous custom classifiers adapt to the unique language, structure, and workflows of the business. They continuously evolve their ability to identify where critical information lives and how it moves. This enables more precise and proactive data protection strategies.
What are pre-trained classifiers?
Proofpoint’s pre-trained classifiers provide an effective and efficient way to identify and protect business-critical documents. These include source code, accounting and tax documents, employee files, agreements, and contracts. Our AI-driven classifiers are powered by LLMs that categorize documents at line speed. By combining open-source AI models with proprietary algorithms and a process that lets you validate results, Proofpoint can identify a document’s purpose and categorize it with 85% confidence or greater.
You can use pre-trained LLM classifiers in DLP policies to protect new or previously overlooked content—without needing prior classification. This saves time and effort. When combined with pattern matching, LLM classifiers also help reduce false positives. For example, with Proofpoint Enterprise DLP, you can let your HR team share sensitive documents internally, while automatically removing permissions if those documents are shared outside the team.
LLM-enriched alerts also help analysts triage and investigate incidents more quickly. For example, if an alert is triggered by Social Security number pattern matching, Enterprise DLP can identify whether the document relates to income tax, a patient form, or a credit application.
However, pre-trained LLM classifiers can have limitations. Because they rely on static enterprise data and fixed labels, they don’t adapt well to evolving threats or changing business contexts or document purposes. They can miss subtle signals, leading to misclassification or false positives. That’s why Proofpoint is now also offering autonomous custom classifiers.
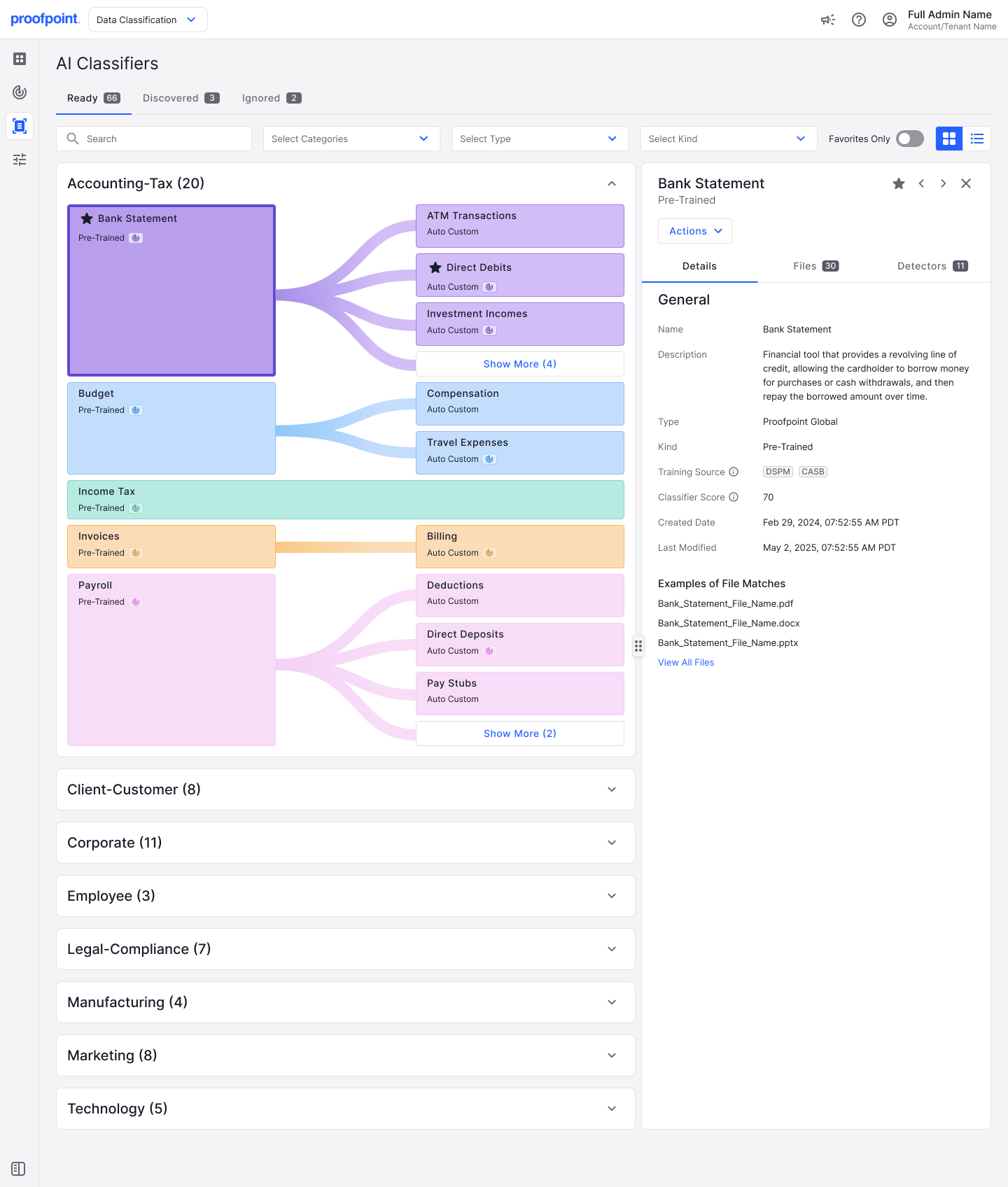
Figure 1: Pre-trained AI classifier for Bank Statement under the Accounting-Tax document category.
What are autonomous custom classifiers?
Proofpoint’s auto learning classifiers are designed to identify information that’s new or unique to your organization. They continuously adapt by observing real-time interactions, access patterns and behavioral context. This results in more accurate, dynamic, and resilient data classification —with minimal human input.
Building on pre-trained LLM classifiers, autolearning classifiers dynamically refine their own models by observing an organization’s hidden data patterns. Using generative AI, they can predict and automatically name new data and document categories. These might include new PII formats or new research papers.
This AI-powered approach enables our data security solution to continually improve classification accuracy based on live data context, leading to fewer false positives and coverage gaps. And because it integrates seamlessly with Proofpoint Enterprise DLP and Data Security Posture Management, it not only classifies sensitive content but also enforces real-time adaptive protections and proactively strengthens security posture. These protections include revoking excessive access privileges or flagging high-risk document or data categories. The result is a fully automated, scalable defense against data exfiltration and exposure.
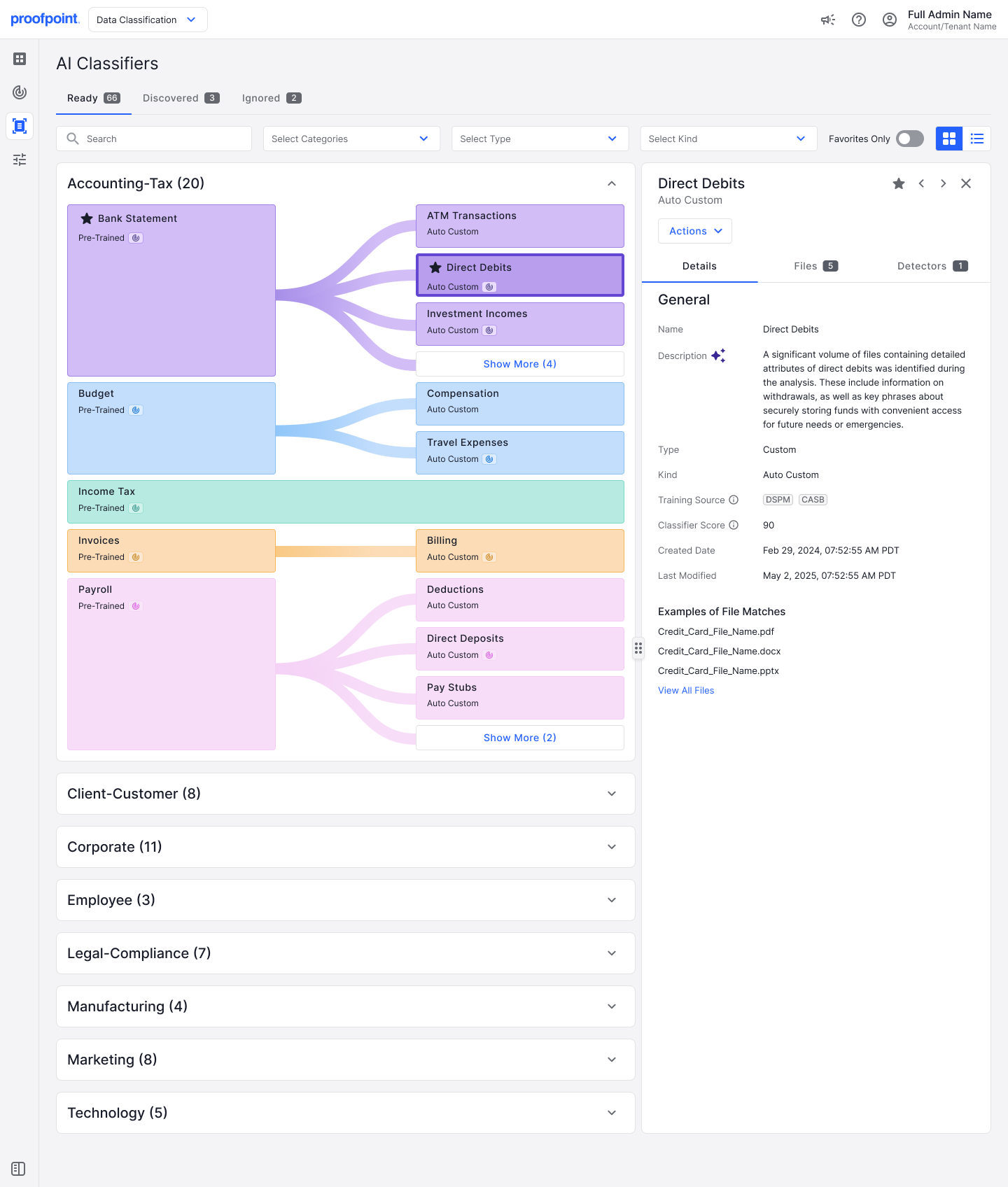
Figure 2: Autonomously named AI classifier for Direct Debits, a sub-category under the Bank Statement category.
How do autonomous custom classifiers help you balance innovation with privacy?
Autonomous custom classifiers learn from behavioral patterns and contextual signals without exposing sensitive content. By sharing only anonymized or aggregated insights, they reduce privacy risks while still improving classification accuracy. This approach enables adaptive data protection that doesn’t compromise confidentiality or regulatory compliance.
How does Proofpoint’s AI-driven, unified data security approach help?
AI-powered data and document classification is the essential first step toward smarter, agent-driven data security and compliance. It works like the sensory system of your enterprise—enabling automated security agents (the nervous system) to see, understand, and respond to risks. By making sense of data, these classifiers enable security agents to act with intelligence and precision.
Without accurate classification, AI agents don’t have the context they need to enforce policies, detect anomalies, or respond to threats. AI classifiers solve this by identifying sensitive information—such as PII, PHI, PCI, source code, and documents new or unique to your organization—across cloud apps, endpoints, email, and storage. They enable real-time categorization and labelling. This informs downstream actions such as blocking risky file transfers, revoking access, escalating insider incidents, or applying encryption.
As environments grow more complex and dynamic, AI-powered classification can scale to handle petabytes of data and millions of files and messages. They can provide continuous insights to agentic security systems. In turn, AI agents can adjust policies and responses based on the classification’s confidence, severity, and regulatory mapping. This helps ensure compliance with frameworks such as the General Data Protection Regulation (GDPR), Health Insurance Portability and Accountability Act (HIPAA), and California Consumer Privacy Act (CCPA), without constant manual reconfiguration.
Just as the body can't react to danger without sensory input, autonomous data security can't function without understanding what data and documents it’s protecting. AI-powered classification provides the vision and awareness that enable security and compliance agents to act quickly, accurately, and at scale.
Learn more
To learn more about our AI-powered classifiers and Proofpoint Data Security, view the Defend Data Innovations webinar.