
Unternehmen haben zunehmend Schwierigkeiten, geschäftskritische Informationen wie geistiges Eigentum und Geschäftsgeheimnisse zu schützen, da herkömmliche Datensicherheitssysteme hauptsächlich entwickelt wurden, um strukturierte Datentypen wie personenbezogene Daten, Gesundheitsdaten und Zahlungskartendaten zu identifizieren und zu schützen. Diese Systeme sind nicht geeignet, unstrukturierte Daten wie Dokumente zu verarbeiten, da sie sich auf diskrete Datenelemente konzentrieren und den allgemeinen Kontext oder Zweck der Informationen außen vor lassen. Wichtiger ist jedoch, dass sie Schwierigkeiten haben, sensible Geschäftsdokumente zu identifizieren, wenn diese nicht vordefinierten Mustern entsprechen.
Dank KI-gestützten Klassifizierern ändert sich das. Sie verwenden Large Language Models (LLMs), die mit großen Datensätzen mit Unternehmensdokumenten trainiert wurden. Dadurch lernen sie, differenzierte Dokumenttypen zu erkennen, z. B. Geschäftsgeheimnisse, medizinische Formulare, Compliance-Dokumente und Verträge. KI-gesteuerte Klassifizierer beschränken sich nicht auf Schlüsselwörter, sondern ordnen Dokumenten anhand von Kontext und semantischem Verständnis eine Geschäftsfunktion und Absicht zu. Wenn sie weiter mit den Daten eines Unternehmens trainiert werden, passen sich diese selbstlernenden Klassifizierer an die spezifische Sprache, Struktur und die Arbeitsabläufe des Unternehmens an. Dadurch erweitern sie kontinuierlich ihre Möglichkeiten, den Speicherort und die Übertragung kritischer Informationen zu identifizieren, was präzisere und proaktivere Datenschutzstrategien ermöglicht.
Was sind vortrainierte Klassifizierer?
Die vortrainierten Klassifizierer von Proofpoint bieten eine effektive und effiziente Möglichkeit zum Identifizieren und Schützen geschäftskritischer Dokumente wie Quellcode, Buchhaltungs- und Steuerdokumente, Mitarbeiterakten, Vereinbarungen und Verträge. Unsere KI-gestützten Klassifizierer kategorisieren die Dokumente mithilfe von LLMs in Echtzeit. Durch die Kombination von Open-Source-KI-Modellen mit proprietären Algorithmen und einem Validierungsprozess für die Ergebnisse kann Proofpoint den Zweck eines Dokuments identifizieren und es mit einer Zuverlässigkeit von 85 % oder höher kategorisieren.
Sie können vortrainierte LLM-Klassifizierer in DLP-Richtlinien verwenden, um neue oder zuvor übersehene Inhalte zu schützen – ohne zuvor eine Klassifizierung vornehmen zu müssen, was Zeit und Aufwand spart. In Kombination mit Musterabgleichen können LLM-Klassifizierer auch Fehlalarme reduzieren. Zum Beispiel können Sie mit Proofpoint Enterprise DLP Ihrer Personalabteilung erlauben, sensible Dokumente intern weiterzugeben, während die Berechtigungen automatisch entfernt werden, wenn diese Dokumente außerhalb der Abteilung weitergegeben werden.
Analysten können mithilfe von Warnmeldungen, die mit LLM angereichert wurden, Vorfälle schneller triagieren und untersuchen. Wenn beispielsweise der Musterabgleich eine Sozialversicherungsnummer erkennt und eine Warnmeldung auslöst, lässt sich mit Proofpoint Enterprise DLP feststellen, ob das Dokument mit der Einkommenssteuer, einem Patientenformular oder einem Kreditantrag im Zusammenhang steht.
Vortrainierte LLM-Klassifizierer können jedoch auch Einschränkungen haben. Da sie auf statischen Unternehmensdaten und festen Kennzeichnungen basieren, passen sie sich nur unzureichend an neue Bedrohungen oder sich ändernde Geschäftskontexte oder Dokumentationszwecke an. Sie können subtile Signale übersehen, was zu Fehlklassifizierungen oder Fehlalarmen führt. Deshalb werden selbstlernende Klassifizierer immer wichtiger.
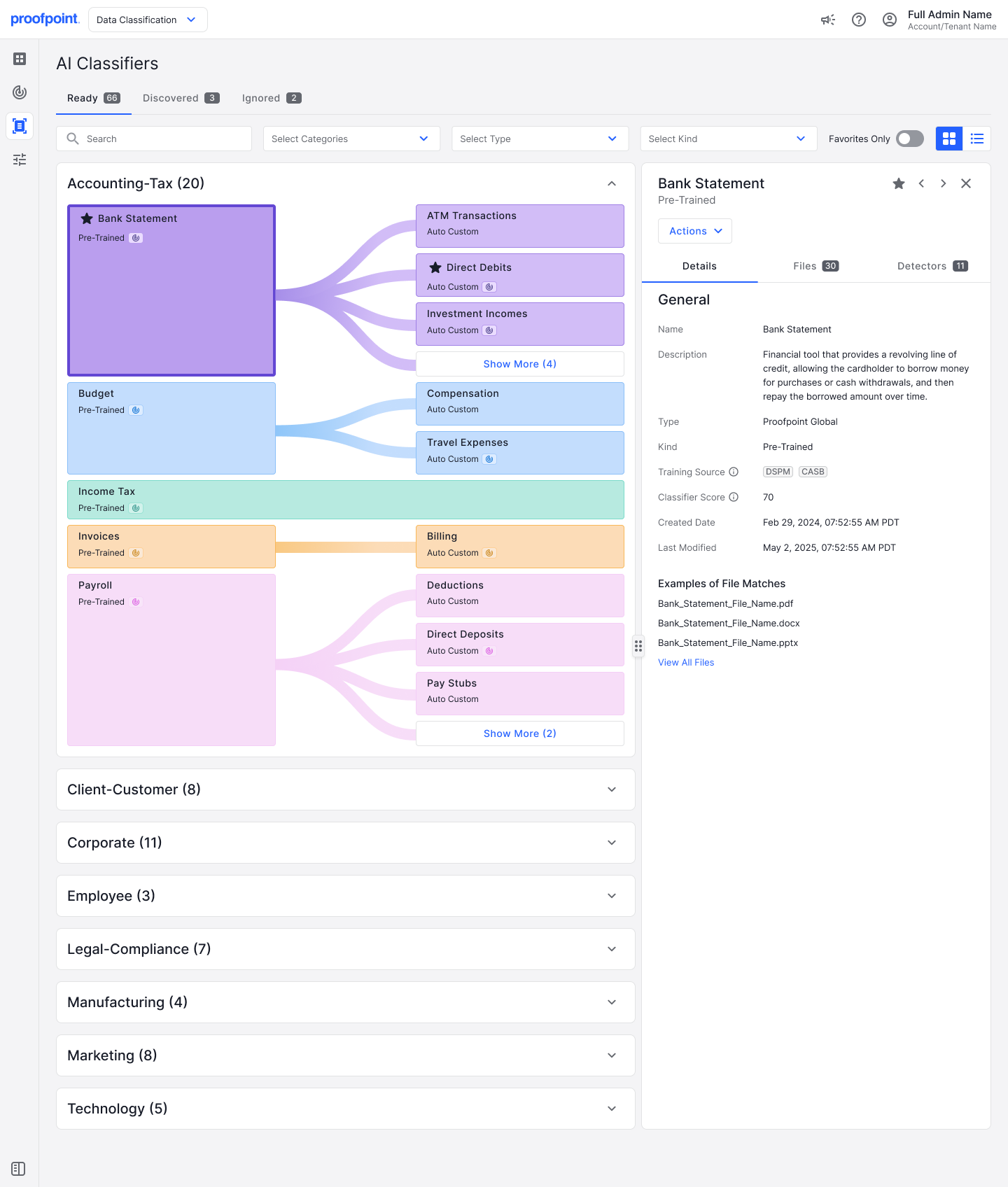
Abb. 1: Vortrainierter KI-Klassifizierer für Kontoauszüge unter der Dokumentkategorie „Buchhaltung-Steuer“.
Was sind selbstlernende Klassifizierer?
Die selbstlernenden Klassifizierer von Proofpoint sind darauf ausgelegt, Informationen zu identifizieren, die für Ihr Unternehmen neu oder einzigartig sind. Sie passen sich kontinuierlich an, indem sie Echtzeit-Interaktionen, Zugriffsmuster und den Verhaltenskontext beobachten. Dies ermöglicht eine genauere, dynamische und zuverlässige Datenklassifizierung – mit minimalem Anwendereingriff.
Aufbauend auf vortrainierten LLM-Klassifizierern optimieren selbstlernende Klassifizierer dynamisch ihre eigenen Modelle, indem sie die verborgenen Datenmuster eines Unternehmens auswerten. Mithilfe generativer KI können sie neue Daten- und Dokumentkategorien vorhersagen und automatisch benennen, z. B. neue Formate für personenbezogene Daten oder neue Forschungsarbeiten.
Dank dieses KI-gestützten Ansatzes ist unsere Datensicherheitslösung in der Lage, die Klassifizierungsgenauigkeit mithilfe von Echtzeitdatenkontext kontinuierlich zu verbessern, was zu weniger Fehlalarmen und Abdeckungslücken führt. Und da sie sich nahtlos mit Proofpoint Enterprise DLP und Data Security Posture Management integriert, klassifiziert sie nicht nur sensible Inhalte, sondern setzt auch adaptive Echtzeitschutzmaßnahmen durch, z. B. den Entzug übermäßiger Zugriffsrechte oder das Kennzeichnen von Dokument- oder Datenkategorien mit hohem Risiko. Das Ergebnis ist vollständig automatisierter, skalierbarer Schutz vor Datenexfiltration und -kompromittierung.
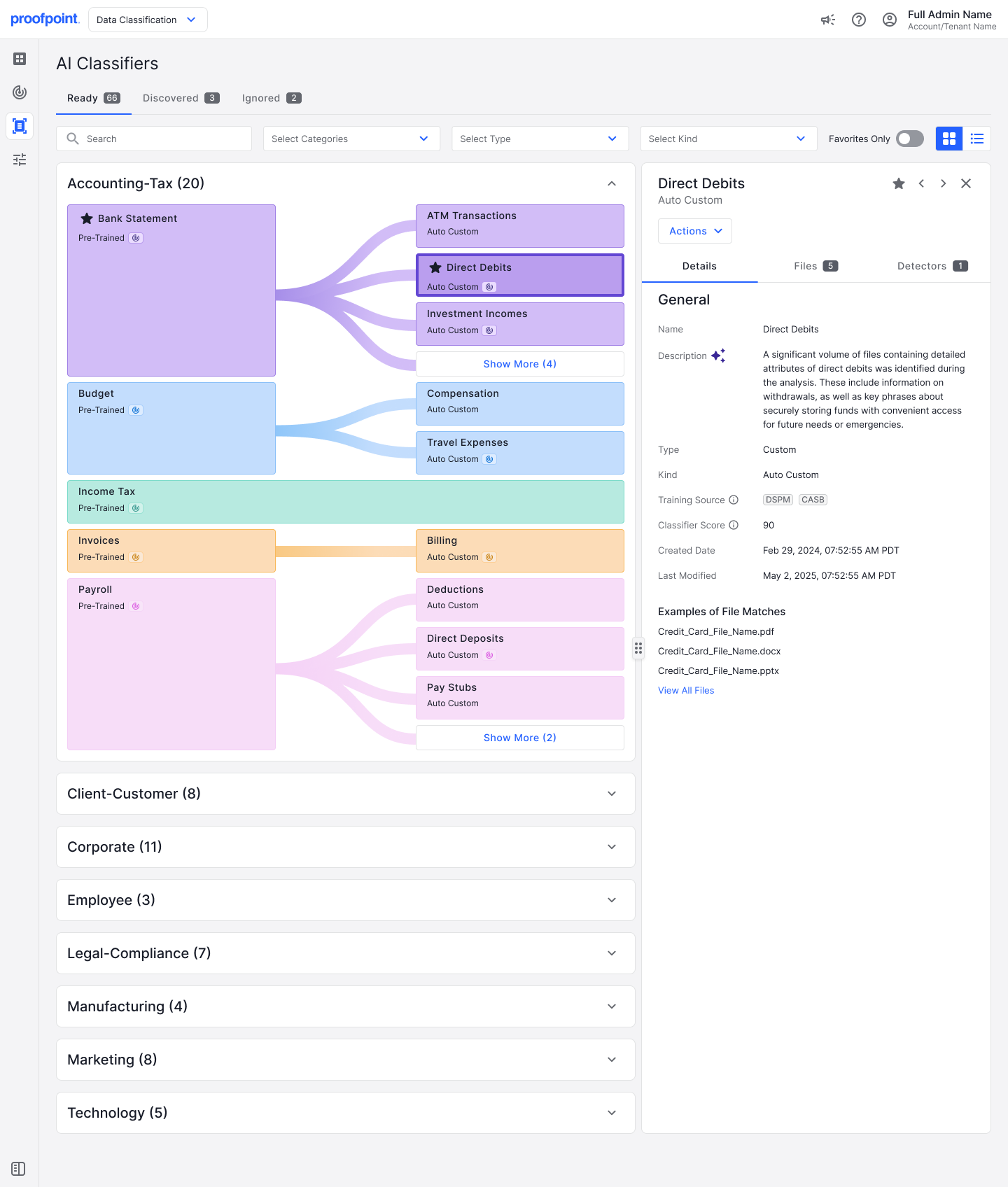 Abb. 2: Automatisch erlernte und benannte KI-Klassifizierer für Lastschriften, eine Unterkategorie der Kategorie „Kontoauszug“.
Abb. 2: Automatisch erlernte und benannte KI-Klassifizierer für Lastschriften, eine Unterkategorie der Kategorie „Kontoauszug“.
Wie bringen automatisch lernende Klassifizierer Innovation mit Datenschutz in Einklang?
Automatisch lernende Klassifizierer lernen aus Verhaltensmustern und Kontextsignalen, ohne sensible Inhalte offenzulegen. Da Erkenntnisse nur anonymisiert oder aggregiert weitergegeben werden, minimieren sie Datenschutzrisiken und verbessern gleichzeitig die Klassifizierungsgenauigkeit. Dies ermöglicht adaptiven Datenschutz, der weder die Vertraulichkeit noch die Einhaltung gesetzlicher Vorschriften gefährdet.
Welche Vorteile bietet der KI-gestützte, einheitlichen Proofpoint-Datensicherheitsansatz?
KI-gestützte Daten- und Dokumentklassifizierung ist der erste wesentliche Schritt zu intelligenterer, agentenbasierter Datensicherheit und Compliance. Sie agiert als sensorisches System Ihres Unternehmens und erlaubt automatisierten Sicherheitsagenten (dem Nervensystem), Risiken zu sehen, zu bewerten und darauf zu reagieren. Klassifizierer machen Daten verständlich, sodass Sicherheitsagenten intelligent und präzise handeln können.
Ohne genaue Klassifizierung verfügen KI-Agenten nicht über den notwendigen Kontext, um Richtlinien durchzusetzen, Anomalien zu erkennen oder auf Bedrohungen zu reagieren. KI-Klassifizierer lösen dieses Problem, indem sie sensible Informationen wie Personen-, Gesundheits- und Zahlungskartendaten, Quellcode und für Ihr Unternehmen neue oder einzigartige Dokumente auf Endpunkten, in Cloud-Anwendungen, E-Mails und Datenspeichern identifizieren. Sie ermöglichen die Datenkategorisierung und -kennzeichnung in Echtzeit, was nachgelagerte Maßnahmen wie das Blockieren riskanter Dateiübertragungen, das Widerrufen von Zugriffsrechten, das Eskalieren von Insider-Vorfällen oder das Anwenden von Verschlüsselung unterstützt.
Da Umgebungen immer komplexer und dynamischer werden, kann die KI-gestützte Klassifizierung skaliert werden, um Petabytes an Daten und Millionen von Dateien und Nachrichten zu verarbeiten. Sie kann kontinuierliche Einblicke in agentenbasierte Sicherheitssysteme liefern, während im Gegenzug KI-Agenten die Richtlinien und Gegenmaßnahmen basierend auf dem Vertrauen, dem Schwergrad und der regulatorischen Zuordnung der Klassifizierung anpassen. Das gewährleistet die Einhaltung von Vorschriften wie der Datenschutz-Grundverordnung (DSGVO), dem Health Insurance Portability and Accountability Act (HIPAA) und dem California Consumer Privacy Act (CCPA), ohne dass eine ständige manuelle Neukonfiguration erforderlich ist.
So wie der Körper ohne sensorische Informationen nicht auf eine Gefahr reagieren kann, muss autonome Datensicherheit verstehen, welche Daten und Dokumente sie schützt. KI-gestützte Klassifizierung bietet die Übersicht und die Einblicke, mit denen Sicherheits- und Compliance-Agenten schnell, genau und im beliebigen Maßstab handeln können.
Weitere Informationen
Weitere Informationen über unsere KI-gestützten Klassifizierer und Proofpoint Data Security erhalten Sie in unserer-Reihe Webinar Defend Data: Innovations (Daten schützen: Innovationen).