
Engineering Insights is an ongoing blog series that gives a behind-the-scenes look into the technical challenges, lessons and advances that help our customers protect people and defend data every day. Each post is a firsthand account by our engineers.
As business grows increasingly digital, data volumes are growing at an exponential rate. To keep up, companies need scalable infrastructure to efficiently process and derive value from that data. That’s why we developed Data Grinder. The platform provides a robust and flexible data processing architecture to:
- Read large volumes of data
- Execute customized processing through pluggable applications
- Generate actionable insights
Data Grinder can extract, process and manage data across many scenarios. This makes it a valuable tool for seamlessly processing data at scale.
This blog post’s aims are twofold. First, we explore the key capabilities of Data Grinder; second, we explain how it’s used to deliver mission-critical data applications at scale.
The need for fast and reliable data processing
In some ways, data management is like handling medical records. Think of it like this:
- Hot data is frequently accessed—like patients’ vital signs.
- Warm data is used sometimes—like test results for ongoing treatment.
- Cold data is rarely accessed—like old records from discharged patients.
In the same way, data processing speeds are defined as follows:
- Real time for instant service-to-service interactions
- Near real time for tasks which need to complete quickly but not instantaneously
- Batch for non-urgent scheduled jobs
At Proofpoint, the Infobus enables real-time data exchange between services. It works like Apache Kafka, which offers similar functionality. Our teams build real-time or near-real-time pipelines to process Infobus data for various use cases.
We have several applications that rely on near-real-time processing. Some examples are:
- Spyhunter. This app monitors billions of messages for thousands of indicators of advanced persistent threats (APTs).
- SpamAnomaly. Its main job is to alert on anomalous spam rule patterns and spot potential issues as they arise.
- Enrichment. This app enriches messages that are processed by Proofpoint with data that has been extracted from various data sources.
These apps share several things in common. First, each one consumes large volumes of data. Second, each one processes that data. And finally, each one carries out an action, such as updating a datastore, which enables various interactions.
The Data Grinder platform
Data Grinder applications can detect anomalies in email traffic, identify cyber threats, enable complex data queries and more. The main purpose of the Data Grinder platform is to enable applications to read and process event data at scale.
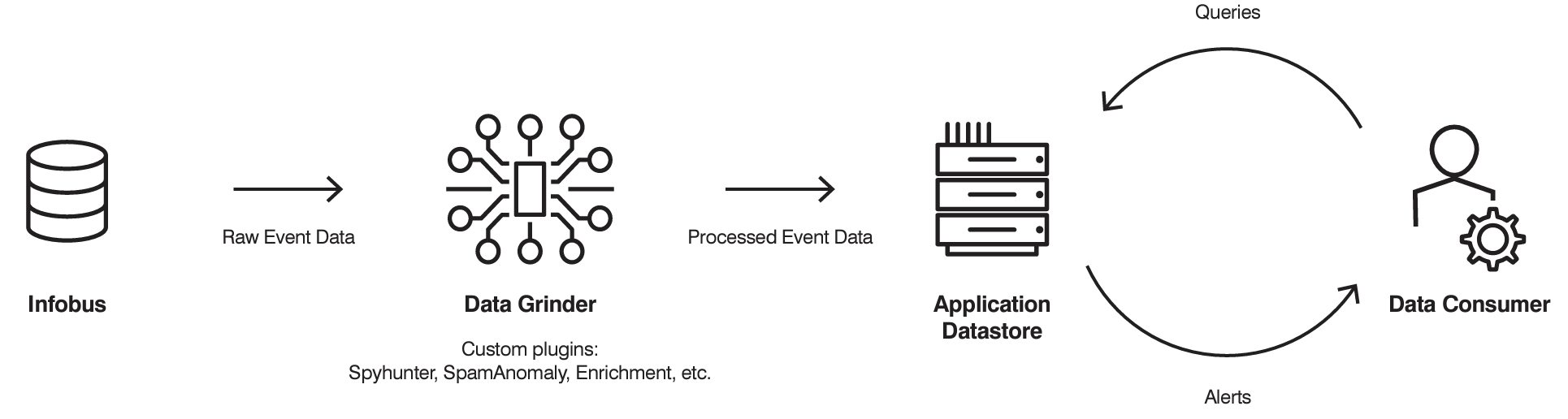
Overview of the Data Grinder workflow.
Data Grinder plug-ins implement application-specific logic. They can send alerts, update an application-specific datastore or carry out other actions needed to support the application's use case.
Essential functions, such as reading from the Infobus and handling failures, are consistent across different use cases. But the pluggable architecture also allows for tailored implementations, which are then packaged as plug-ins. Data Grinder takes a consistent approach to passing data to each plug-in. That means every plug-in needs to implement only one method:
grind(data).
The grind method provides the logic for how to process the input data. It also specifies whether to write to another datastore and, if so, what that logic should be. These plug-ins can streamline processes and enable common alert behaviors.
Keeping costs and errors in check
Data Grinder is optimized for total cost of ownership (TCO). As such, it’s meant to help minimize costs and reduce errors. It handles complexities such as large variations in data traffic. And it enables features such as auto-scaling. By abstracting common functions, it reduces the challenges in deploying new plug-ins and maintaining code.
For example, Data Grinder monitors performance metrics. It publishes alerts when any of its plug-ins exhibit anomalies, such as slowdowns or logging errors.
These common requirements are available to Data Grinder plug-ins out of the box. Each plug-in can be tailored for specific needs at a low implementation cost. This allows for specialized handling of specific tasks within the system with minimal deviance from the common pattern.
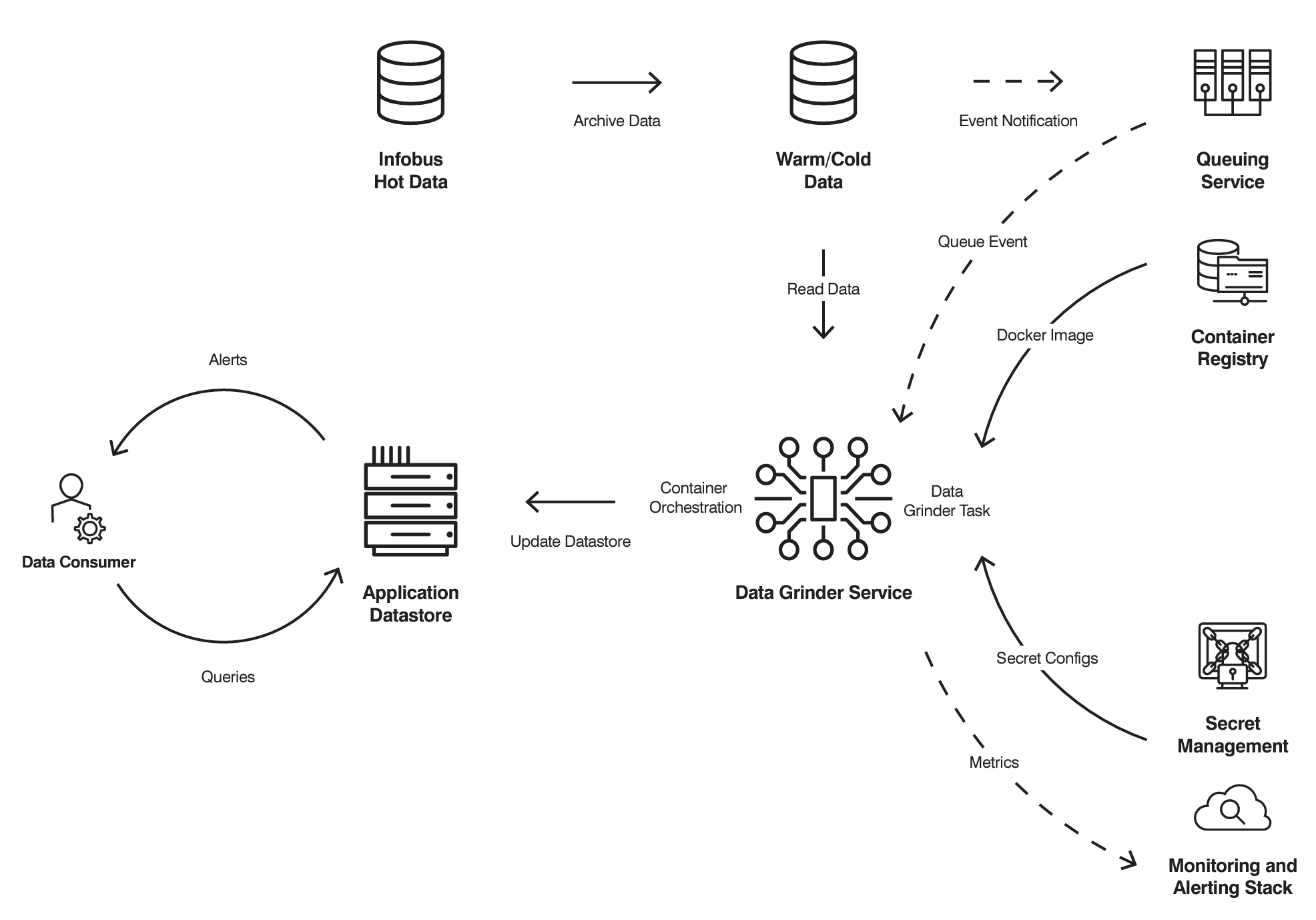
Example of a near-real-time Data Grinder data flow. In real-time data flows, Data Grinder consumes data from the Infobus, which also manages the queueing.
The process of managing large amounts of data in transit is complex. But Data Grinder has features to streamline this process. The platform’s plug-ins run inside Docker containers, and Data Grinder is flexible enough to allow one or more plug-ins per container. This grouping feature allows for more efficient use of resources. (For example, multiple plug-ins can share process memory.)
Data Grinder auto scales through container orchestration systems such as AWS Elastic Container Service (ECS). So it can adjust resources per plug-in as needed. This features helps ensure data resilience and monitoring of performance metrics. This includes queueing data via services such as AWS Simple Queuing Service (SQS) to make sure there is no data loss in the event of data processing issues or during scheduled maintenance.
A scheduling system for smart jobs
Data Grinder implements a smart job-scheduling system called JobManager to run data processing tasks—or “jobs”—efficiently. Each job runs a Data Grinder plug-in that performs a specific data-handling function:
- Jobs that are IO-bound—meaning that they spend most of their time reading and writing data—are assigned to multiple threads to maximize throughput.
- Jobs that are CPU- or memory-bound can saturate a single container, so Data Grinder runs them in separate containers to avoid contention.
Data Grinder optimizes how jobs are executed to make the best use of computing resources. Developers define the plug-ins. JobManager handles scheduling within each container automatically. And the container orchestration platform manages the auto-scaling. These abstractions make it easy to process huge datasets efficiently.
The result is a data processing platform that abstracts away the complexity of distributed, multi-threaded software architectures. Data scientists and developers can focus on creating plug-ins for data transformation tasks and let Data Grinder handle many of the “under the hood” complexities.
With Data Grinder, we can scale data applications with high efficiency, running trillions of operations daily. This scalability helps ensure that the system can handle varying demands and complexities.
Transforming raw data into actionable insights
Data Grinder manages email traffic patterns, detects anomalies and annotates data. It streamlines the development and deployment of robust, scalable data applications. Using just one method, grind(data), developers can build custom plug-ins that seamlessly plug into Data Grinder.
This abstraction of common infrastructure requirements empowers Data Grinder plug-ins to focus on their core logic for transforming raw data into actionable insights. The platform is built to handle the heavy lifting of distributed processing, scaling and resilience.
About the authors

Alec Lebedev is an Engineering Architect at Proofpoint in charge of data strategy. He spearheads the development of distributed data, application and machine learning platforms, delivering data as a product. He designed a cloud-based data ecosystem that extracts business value and actionable insights from exabytes of data. Alec’s leadership in these innovative areas, coupled with his hands-on training of engineering and operations teams, illustrates his technical mastery and collaborative expertise.

Adam Starr leads the machine learning and artificial intelligence teams for the Security Products Group at Proofpoint. Adam’s team develops many of the detection systems the company’s core email security offerings: Email Protection, TAP and Threat Response. He brings a unique blend of technical expertise, strategic leadership and adventurous spirit to the cybersecurity field. Adam’s understanding of complex mathematical and computing principles, combined with his hands-on experience in threat detection and prevention, offers unique insight into the cyber landscape. Adam received his Bachelor of Arts in Mathematics from Pomona College and is an MBA candidate at Stanford University.