
Engineering Insights is an ongoing blog series that gives a behind-the-scenes look into the technical challenges, lessons and advances that help our customers protect people and defend data every day. Each post is a firsthand account by one of our engineers about the process that led up to a Proofpoint innovation.
The ML Labs organization works with each product group at Proofpoint to infuse machine intelligence into our broad portfolio. This is an account of how we worked with the Proofpoint Intelligent Compliance product team to develop and deploy our Promissory Images classifier within Proofpoint Patrol. The solution helps detect threats and ensure compliance within social media data—including images.
The ask
In 2018, a financial services firm had a feature request: it needed to flag social media images posted by employees that made any kind of financial promise.
FINRA, a governing body that aims to protect investors, had expanded its guidance around such promissory statements to include images. As the body put it: “No member may make any false, exaggerated, unwarranted, promissory or misleading statement or claim in any communication.”
The customer needed an image classifier to monitor whether employees were following that guidance, including any images they used to communicate. Such promissory images convey or imply guarantees of financial gain from investing in a specific instrument or working with an advisor or firm. These promises can be denoted in many ways: from stacks of gold coins and overflowing piggy banks to rising profit charts and money pouring like rain.

Source: Public Domain.
Caption: Examples of images communicating positive financial outcomes.
After we learned what constitutes promissory images, we set out to teach our machine learning (ML) model to do the same. We labeled a small batch of social media images as either promissory or not promissory. We then used that dataset to train our first model: a binary image classifier.
The theory
Our first model used convolutional neural networks (CNNs) and transfer learning. The CNN architecture consists of layers of filters that match patterns present in the output of the preceding layer.
Lower filters encode lower-level, syntactical features such as edges and shapes; higher filters encode higher-level, semantic features such as objects and faces. Transfer learning uses the lower-level features learned from a large, generic labeled dataset as a competitive starting point for further training with the smaller, task-specific dataset. Further training, or finetuning, allows the higher layers to learn task-specific semantic features.
In the following image, the filter weights in the lowest (left) to highest (right) layer of a three-layer neural network trained on images of faces.
Layer 1 contains edge detectors. Layer 2 contains face part detectors. And layer 3 contains various face shape detectors. Neural networks build syntactical features into semantic features.

We finetuned a CNN model pre-trained on the ImageNet dataset using our labeled promissory image dataset. Then we evaluated it on our validation set.
It performed terribly. But why?
The flop
Our first model flopped because we chose a semantic tool to solve a conceptual problem. CNNs use syntactical features (such as edges and shape detectors) to build understanding about semantic objects (such as bar charts and dollar signs).
Not all bar charts are promissory. Nor are all dollar signs. But our binary classifier consistently categorized both objects as such. It simply couldn’t classify concepts given the small batch of data we had available.
As we delved further into the problem, the reason quickly became clear. A promissory image conveys a concept. This concept is determined by the spatial relationship between semantic features or objects. For example, large dollar signs in a chart convey the financial promissory concept; small dollar signs along the bar chart axis convey the economic report concept.
We needed a conceptual image classifier that could capture the spatial relationship between objects. That meant going beyond binary classification.
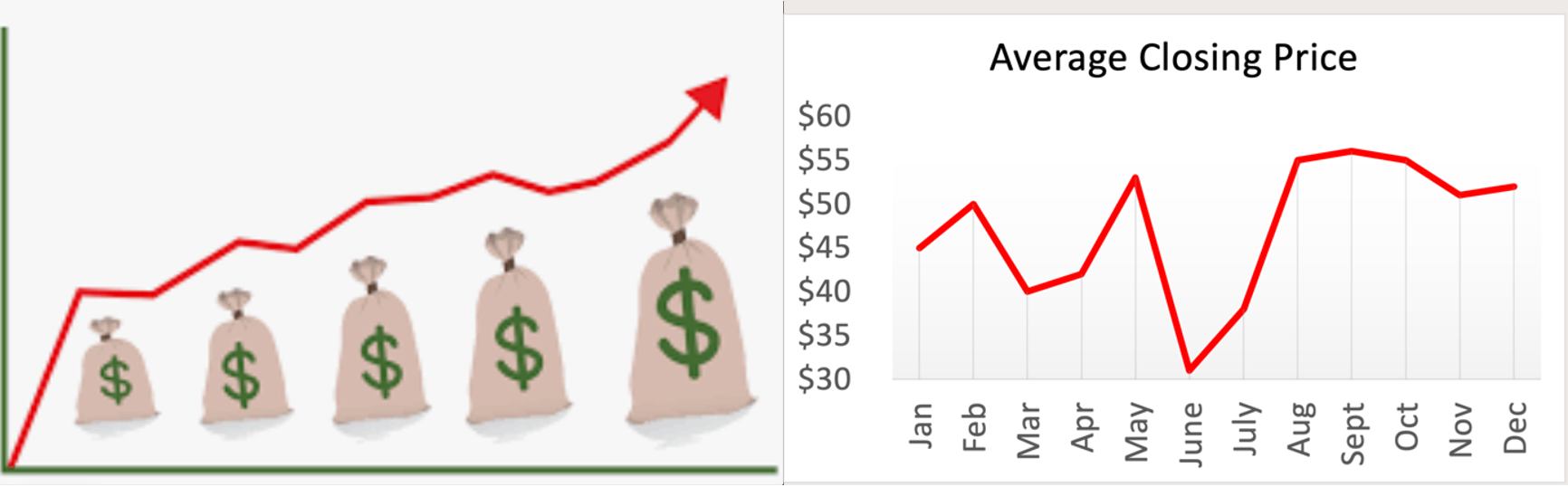
Caption: Line graphs containing dollar signs. The image on the left is promissory, while the image on the right is not promissory. Our binary classifier struggled to differentiate them.
At the same time, we also wanted to guard against learning spurious features with an architecture that accepted spatially denser labels. Spurious features are useful in prediction but not fundamental to the task; they decrease a model’s ability to generalize effectively to new data. For example, our model latched onto a spurious feature: red lines. So it wrongly classified all graphs with a red line as promissory.
During a training iteration, the image passes through the layers of the CNN to generate a prediction: promissory or not promissory. The loss between the true label and predicted label is backpropagated through these layers to update the filter weights. In binary classification, the signal from the loss function is not spatially constrained as it is in the object detection paradigm; this lack of constraint permits the model to focus on spurious features.
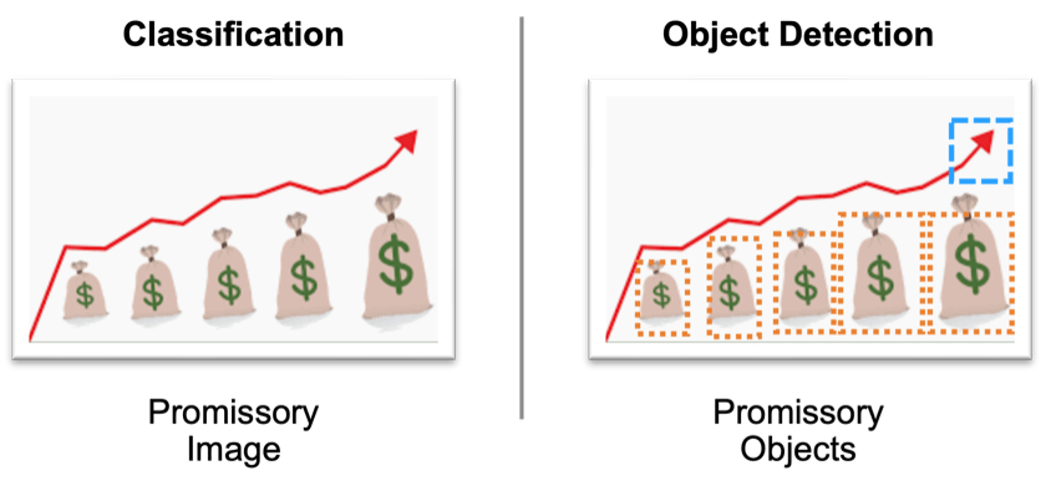
Caption: Image classification looks at image-level labels. Object detection considers object-level labels, which are spatially denser.
For these two reasons, we believed that switching from binary classification to object detection would improve the model.
This time, we were right.
The rebound
We designed a second version with the architecture shown in the next diagram.
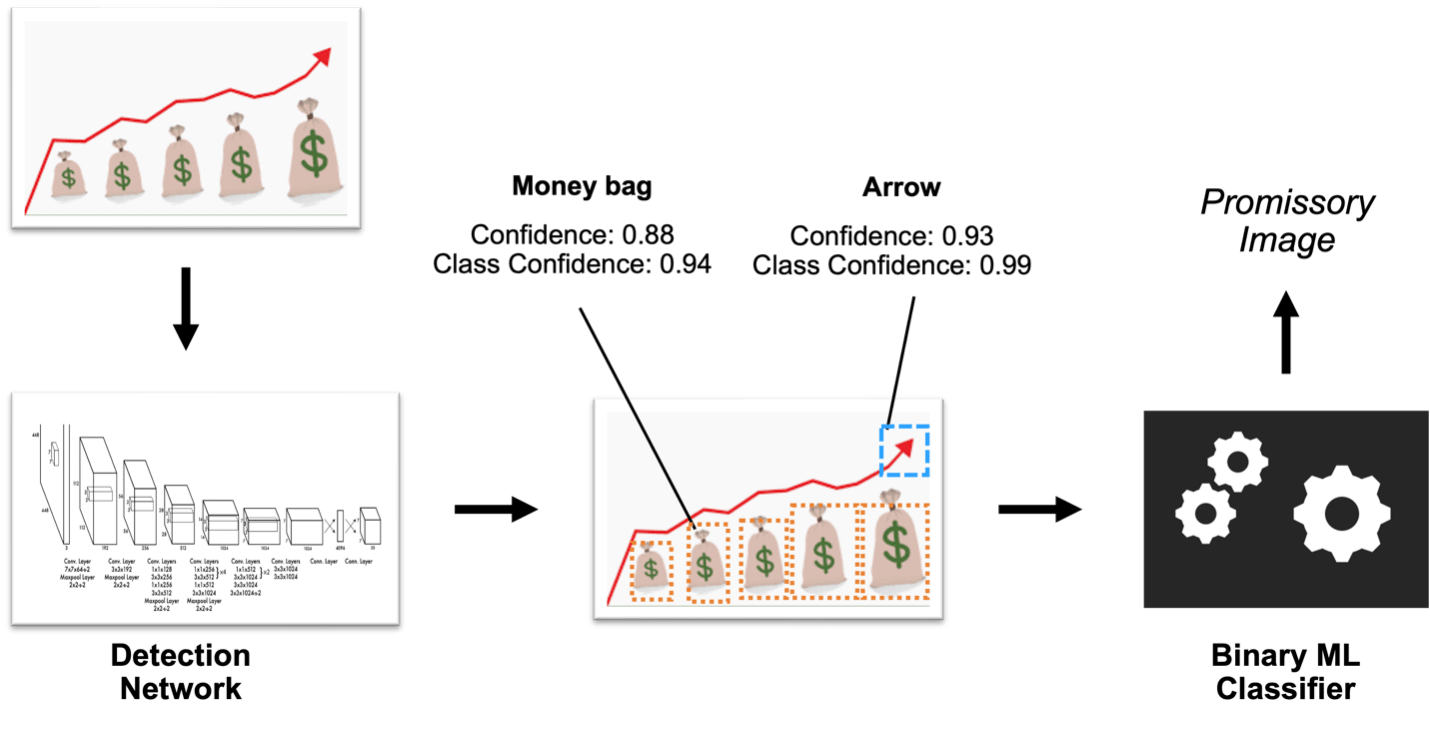
Caption: The patented architecture for the second version of the Promissory Image classifier.
The second version used promissory object detection and conceptual classification. Here’s how it works:
- The object detection network locates promissory objects.
- The ML classifier ingests those locations and metadata.
- The ML classifier then uses that information to capture the spatial relationship between the objects for conceptual classification.
We started by selecting a detection network and ML classifier architecture. We used Prodigy from Explosion AI to label promissory objects in our dataset. And finally we trained the system to achieve production-worthy performance on our validation and test sets.
The second version was a stark improvement over the first. And it grew even better with each new round of data labeling and retraining.
The future
We have run into several challenges since then. These include:
- Scale-independent object detection
- Cohesive serial model training
- Prediction churn prevention
- Detection network latency
- Promissory text detection within an image
Some of these issues have called for innovations in engineering and operations. We have mitigated others with regular data labeling and model retraining. And a few have yet to be solved as we await more powerful models and architectures.
We are eager to see the results of recent advances in transformer models for computer vision applications; they promise increased capacity for conceptual classification without a two-model architecture. The most notable extension of this line of research is GPT-4 and similar large language models.
These advances may well offer predictive capacity with far less data labeling or even model retraining, thanks to prompt engineering and in-context learning. We look forward to releasing a blog post in the coming months on how we are applying these large models across our product line.
Acknowledgements
We have many people to thank in this effort. Brian Jones took part in several insightful discussions about this classifier during the architecture design phases. This classifier would not have made it to production without the operations work done by Sahith Annavarapu. Aamna Tariq and her teammate Tehmina Javed have annotated thousands of images for the new model. And Gautham Gorti worked hard as our summer intern to extend the architecture and establish the retraining pipeline.
About the Author
 Dan Salo is a data science manager within the ML Labs group at Proofpoint. He manages a team of software engineers and data scientists working to detect cyber threats and compliance violations on social media streams and in cloud storage. He holds engineering degrees from Duke University and NC State University. When he’s not on a Zoom call, you can often find him spending time outside with his wife and kids or playing basketball with friends.
Dan Salo is a data science manager within the ML Labs group at Proofpoint. He manages a team of software engineers and data scientists working to detect cyber threats and compliance violations on social media streams and in cloud storage. He holds engineering degrees from Duke University and NC State University. When he’s not on a Zoom call, you can often find him spending time outside with his wife and kids or playing basketball with friends.