
Recently, my team at Proofpoint was trying to find a simple solution to split a database. We wanted a solution that would cause minimal interruption since we had databases running on production. After much deliberation and research, we found a replica-based shard splitting process to be the best solution.
Database shard splitting refers to the process of splitting a single master database into multiple master databases.
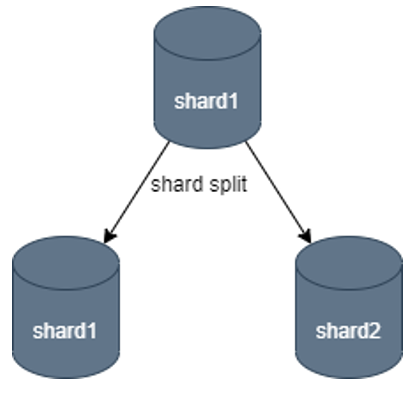
Figure 1. Database shard split
At Proofpoint, we use Amazon RDS (Relational Database Service) to store transactional data; a single database holds several terabytes of data. Managing a big database instance in production is always a challenge from an operational point of view, as there are several issues database administrators and engineers can run into. For example:
- Adding new indexes takes time for big tables, especially when read/writes are heavy.
- Database backups and snapshots become more time-consuming as the database size grows.
- The larger the database, the more likely it is that more customers are being hosted on the single database instance; so, in the case of a database crash, the blast radius can be huge.
To mitigate these challenges, we decided to split the database rather than continue to increase the provisioned disk size for the single database node.
While there are several approaches to create a separate master instance and split the data, we were looking for a simple and safe solution for a database running on production. I came across an article from Amazon Web Services (AWS), “Sharding with Amazon Relational Database Service,” and found it useful for our use case. We were able to split the data on a running system with minimal downtime.
Following are the summary steps to database sharding successfully:
Pre-requisite steps
Note: These pre-requisite steps are only valid if you’ve never created sharding logic for your database and used it in read/write services.
- Assign a shard Identifier to the existing database Instance. This is usually done using configuration property file stored on read and write applications.
db.shard.id=1
db.instance.name=shard1-db.test
- Another approach would be to create database table to store this config map. For example, database_shard table can be created to store the association between shard Identifier and database Instance. The read/write application needs to be updated accordingly to be able to read this information.

Figure 2. database_shard table
- Choose a shard key. This can be a tenant ID, customer ID or user ID, depending on the boundaries to split the data based on the level of isolation required for the product.
- Create shard mapping table with the shard key and integer-based shard ID columns. For instance, if customer ID is shard key, we need to create a customer_shard table to store the association between customer and shard id.
- Assign shard key to a shard ID. A simple approach would be to use a modular based hash function, which takes in a shard key like customer ID and number of available shards and then output shard Id that can be used to map the shard key. This process is generally integrated with application logic, where the new tenant IDs (customers/users) are being added or updated. You could also create a focused microservice for managing the shard assignment.
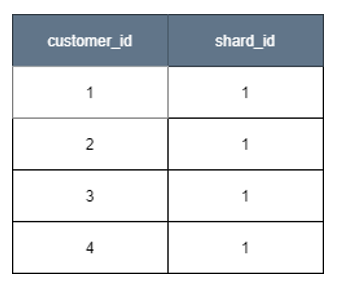
Figure 3. customer_shard table
- Add Query Routing logic on the application code so that it can read the shard mapping table and route read & write queries to appropriate database shard instance.
Migration steps
Following are the migration steps to perform a database shard split:
- Create a new replica for the running master instance to be split. (How to create a read replica on Amazon RDS.)
- Wait until the replica is caught up. (This can take several hours or days depending on the size of the master instance, so monitor the ReplicaLag metric.)
- Once the replica is caught up, proceed to performing the actual migration.
- Pick a suitable time window when production services will be minimally disrupted; then, continue with the migration.
- Stop all the write services. Wait for the replica to catch up, which usually happens immediately after new writes are stopped. (At this point, the ReplicaLag metric will be zero.)
- Since there are no new writes, reads aren’t stale at this point, which means read services can continue to run. And because read API services can continue to serve, there’s essentially no noticeable interruption.
- Promote the read replica into a separate master instance. (How to promote a read replica to a stand-alone master on Amazon RDS.)
- Once the new master instance is ready, all customer data that is needed will have been migrated, along with data that isn’t necessary and will need to be cleaned up post-migration. The new master instance is basically a copy of original database.
- To use the new master instance for the identified set of customers, update both database_shard to assign a shard ID to new master instance and the customer_shard table for the identified set of customer ID rows to point to the new shard ID.
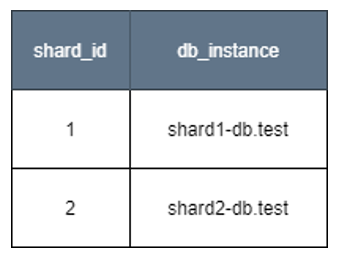
Figure 4. Updated database_shard table
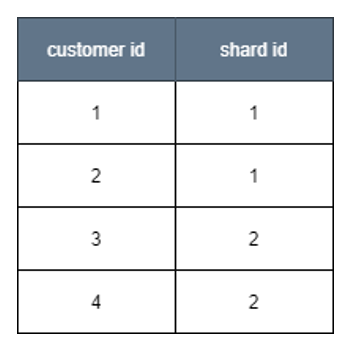
Figure 5. Updated customer_shard table
11. Depending on how the application connects to the database, read services might need to be restarted so that the updated mapping tables can be used.
12. Start the write services for writing to the new master shard for the customer set that was moved.
Post-migration steps
Once the shard splitting process is complete, there is post-migration cleanup to do, since some customer data in the old database shard and the new shard is no longer needed.
For example, in the above steps, customer 3 and 4 data can be removed from the shard1 database, as these IDs have been moved to the new shard2 database. Similarly, customer ID 1 and 2 data can be cleaned up from the newly created shard database, as the original database already has the data for these sets of customers.
You can usually create a script to remove data from all the tables based on the sharding key and schedule it to run as a nightly job. The cleanup process can take several hours to several days, depending on the size of tables.
And there it is—a very simple approach to splitting a single database into multiple databases without any major application traffic interruption.
Join the team
At Proofpoint, our people—and the diversity of their lived experiences and backgrounds—are the driving force behind our success. We have a passion for protecting people, data and brands from today’s advanced threats and compliance risks.
We hire the best people in the business to:
- Build and enhance our proven security platform
- Blend innovation and speed in a constantly evolving cloud architecture
- Analyze new threats and offer deep insight through data-driven intelligence
- Collaborate with our customers to help solve their toughest cybersecurity challenges
If you’re interested in learning more about career opportunities at Proofpoint, visit the careers page.
About the author
Debraj Maity is a Staff Software Engineer at Proofpoint. He is a hands-on technical lead with extensive experience building complex software products and solutions. He holds a Master’s degree in Computer Science from the University of Texas at Dallas. Debraj enjoys outdoor activities such as hiking and nature walking in his free time. He also enjoys reading on various topics, both technical and non-technical.
