
Engineering Insights is an ongoing blog series that gives a behind-the-scenes look into the technical challenges, lessons and advances that help our customers protect people and defend data every day. Each post is a firsthand account by one of our engineers about the process that led up to a Proofpoint innovation.
In the nascent world of large language models (LLMs), prompt engineering has emerged as a critical discipline. However, as LLM applications expand, it is becoming a more complex challenge to manage and maintain a library of related prompts.
At Proofpoint, we developed Exploding Prompts to manage the complexity through exploding template composition. We first created the prompts to generate soft labels for our data across a multitude of models and labeling concerns. But Exploding Prompts has also enabled use cases for LLMs that were previously locked away because managing the prompt lifecycle is so complex.
Recently, we’ve seen exciting progress in the field of automated prompt generation and black-box prompt optimization through DSPy. Black-box optimization requires hand-labeled data to generate prompts automatically—a luxury that’s not always an option. You can use Exploding Prompts to generate labels for unlabeled data, as well as for any prompt-tuning application without a clear (or tractable) objective for optimization.
In the future, Exploding Prompts could be used with DSPy to achieve a human-in-the-loop feedback cycle. We are also thrilled to announce that Exploding Prompts is now an open-source release. We encourage you to explore the code and consider how you might help make it even better.
The challenge: managing complexity in prompt engineering
Prompt engineering is not just about crafting queries that guide intelligent systems to generate the desired outputs; it’s about doing it at scale. As developers push the boundaries of what is possible with LLMs, the need to manage a vast array of prompts efficiently becomes more pressing. Traditional methods often need manual adjustments and updates across numerous templates, which is a process that’s both time-consuming and error-prone.
To understand this problem, just consider the following scenario. You need to label a large quantity of data. You have multiple labels that can apply to each piece of data. And each label requires its own prompt template. You timebox your work and find a prompt template that achieves desirable results for your first label. Happily, most of the template is reusable. So, for the next label, you copy-paste the template and change the portion of the prompt that is specific to the label itself. You continue doing this until you figure out the section of the template that has persisted through each version of your labels can be improved. Now you now face the task of iterating through potentially dozens of templates to make a minor update to each of the files.
Once you finish, your artificial intelligence (AI) provider releases a new model that outperforms your current model. But there’s a catch. The new model requires another small update to each of your templates. To your chagrin, the task of managing the lifecycle of your templates soon takes up most of your time.
The solution: exploding prompts from automated dependency graphs
Prompt templating is a popular way to manage complexity. Exploding Prompts builds on prompt templating by introducing an “explode” operation. This allows a few single-purpose templates to explode into a multitude of prompts. This is accomplished by building dependency graphs automatically from the directory structure and the content of prompt template files.
At its core, Exploding Prompts embodies the “write it once” philosophy. It ensures that every change made in a template correlates with a single update in one file. This enhances efficiency and consistency, as updates automatically propagate across all relevant generated prompts. This separation ensures that updates can be made with speed and efficiency so you can focus on innovation rather than maintenance.
Case study: exploding prompts for automated data labeling
To fully grasp the impact of Exploding Prompts, let’s explore a practical example of using LLMs to generate soft labels for data. (We are actively exploring similar use cases at Proofpoint.)
Consider labeling a dataset for positive and negative sentiment. We will break this discussion into two pieces:
- We will discuss how exploding prompts apply to this soft labeling problem.
- Next, we will describe in detail how the prompt explosion structure is implemented in the filesystem.
1: How exploding prompts apply to the soft labeling problem
“Rendering” is the process of exploding a set of directories and prompt template files into an abundance of prompts. Before we discuss the details of individual files, consider the dependency graph in Figure 1.
After the graph is constructed, rendering starts from the leaf nodes and progresses upward. This ensures that at each step, the rendered attributes from child nodes are fully incorporated into the parent. The root.template node (explained in detail later) is the last to be rendered.
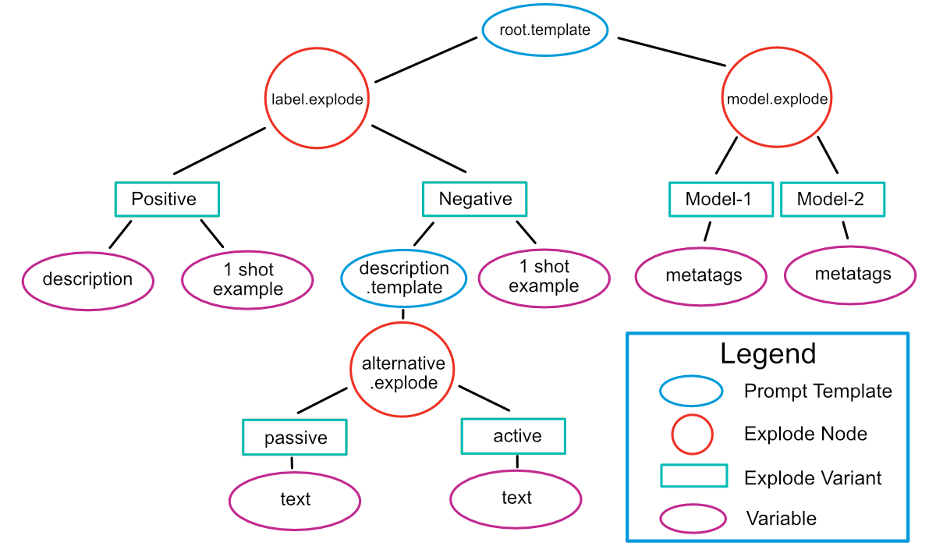
Figure 1: Dependency graph.
The figure is complex, so let’s start by defining the four types of nodes.
- Prompt templates. These are files that end in .template and consist of valid Jinja template text.
- Explode nodes and explode variants. The Explode operation consists of two paired items. These two items always appear together. Every explode variant’s parent is an explode node, and vice versa.
- Explode nodes are directories that end in .explode, each of which adds a dimension to the explosion by indicating a branching operation. In the dependency graph, the parent of an explode node must be a prompt template.
- Explode variants are directories; each defines another state the dimension can occupy.
- Variables. These are the text files that define the text corresponding to Jinja variable names, which are automatically generated from the dependency graph structure. Every leaf node must be a variable. You can use a single YAML file instead of multiple variable files.
This dependency graph generates six prompts corresponding to:
- Positive Model-1
- Positive Model-2
- Negative passive Model-1
- Negative active Model-1
- Negative passive Model-2
- Negative active Model-2
So, what does the root template look like? How do Exploding Prompts infer variable names that Jinja uses? To answer these questions, let’s examine the directory structure and walk through the key files in detail.
2: How the prompt explosion structure is implemented
As shown below, the directory structure is relatively concise and easy to work with. The variable files have been omitted for brevity. Note that the prompt templates live in the same directory as their explode node(s).

Figure 2: Directory structure.
Root.Template
This template serves as the foundation. All prompts that the explode operation generates include the non-parameterized text in the root template. This ensures that each generated prompt adheres to a consistent format, ready to be tailored for specific models and labels. The root template for this example is shown below.
```
{{ model_metatags }}You are a helpful {{ model_name }} assistant. Determine whether the text encapsulated in 3 backticks (```) can be classified as {{ label_name }}.
Definition: {{ label_description }}
Respond in JSON format defined as follows:
{
“{{ label_name }}”: bool # {{ label_description }}
“reasoning”: str # Give the reason why the label applies to the text
}
{{ label_1_shot_example }}
```TEXT
{{ text }}
```
RESULT:
```
Note the variable names, which are automatically defined by the dependency graph (see the first figure). A template can reference objects located in its directory or any subdirectory therein. Variables that are created from exploded templates get their names from the sequence of explode directories that lead to them. They are joined by underscores and exclude the .explode suffix itself. For example, a variable within the root template that pulls from the “label” directory’s description variable would be named label_description.
Additionally, each variant under an explode directory can be referenced with a “name” variable. In our example, variants under label.explode are accessible as label_name. This maps to “Positive” or “Negative,” depending on the variant. “Name” is the only reserved keyword within Exploding Prompts.
Model.explode directory
This explode directory adds the model-required metatags that tell the model how to interpret and respond to the prompt (e.g., “[INST][/INST]” indicating user-defined instructions for the Mistral models).
The explode directory itself has subdirectories that make up the explode variants which correspond to the different models. Any number of variables can be defined for each explode variant. Here, we define only the model-specific “metatags” variables.
When you test your prompts against different models, you may find that more model-specific changes are required to get good results across different LLMs. As a common example, you may find additional instructions are required. In these cases, you could use the model.explode directory to define those differences between model prompts.
Label.explode directory
This directory specifies class definitions and label-specific instructions. In this case, the directory contains the sentiment variants—Positive and Negative.
Each label variant, in turn, defines a description and 1_shot_example. When rendered, they replace the parameters label_description and label_1_shot_example respectively in templates in any ancestor of the label.explode directory.
Alternative.explode directory
Explode directories can be embedded within other explode directories for recursive rendering of templates, as is the case here. Nesting explode directories unlocks recursive template rendering. In our example, this is being used to test variations of a prompt in a single pass. Alternative.explode defines alternative descriptions for the negative sentiment.
Use of a recursive label definition here has the same outcome as creating two Negative labels in the label.explode directory for each variation of negative sentiment. However, by using recursive explosion, both negative sentiment variants share the parent components defined in the negative variant. This is in keeping with the “write it once” philosophy.
The combinatorial explosion of prompt templates
The output of prompt explosion is a set of templates that contains all possible combinations of the various templates and components that make up a given Explode prompt.
Take the simple case of having four different models with 10 different labels. Without Exploding Prompts, we would need to manually create 40 distinct prompt templates. But with Exploding Prompts, the process is streamlined dramatically. By defining just one root template, four model metatag templates and 10 label templates, Exploding Prompts automatically generates all 40 unique prompt templates through its explosive composition mechanism.
In this way, the number of rendered prompts can explode rapidly. For this reason, the final output of Exploding Prompts includes metadata about which explode variants were used to produce the prompt. It is then a trivial exercise for the reader to filter on a desired subset of prompts. In resource-constrained environments, random sampling of exploded prompts can be used for approximate optimization.
Making use of a few templates to generate many variations significantly reduces the number of templates that need to be managed. It also ensures that any update to a label or model template automatically propagates to all relevant prompts. For example, if you need to add a new class label to the sentiment application above, simply creating a new subdirectory in the “label.explode” directory is all that’s needed to generate all associated prompts across different models.
Looking ahead: open-source release and community collaboration
At Proofpoint, we have found Exploding Prompts to be a useful tool to mitigate the complexity of prompt lifecycle management. With the open-source release, we hope to enable others to find new and innovative ways to apply Exploding Prompts to solve real-world problems.
We look forward to your contributions and feedback and to see what diverse applications emerge from the Exploding Prompts project with your help!
Join the team
At Proofpoint, our people—and the diversity of their lived experiences and backgrounds—are the driving force behind our success. We have a passion for protecting people, data and brands from today’s advanced threats and compliance risks.
We hire the best people in the business to:
- Build and enhance our proven security platform
- Blend innovation and speed in a constantly evolving cloud architecture
- Analyze new threats and offer deep insight through data-driven intelligence
- Collaborate with our customers to help solve their toughest cybersecurity challenges
If you’re interested in learning more about career opportunities at Proofpoint, visit the careers page.
About the author

Jason Cronquist is a senior machine learning engineer at Proofpoint, where he enhances machine learning applications spanning threat detection and research. His day-to-day is spent at all levels of abstraction, from disassembling malware to optimizing inference costs of cutting-edge generative AI models. In his free time, Jason enjoys the crisp air of upstate New York while walking his labradoodle, Nova.