 us:
English: Americas
us:
English: Americas











Large language models (LLMs) are becoming foundational to email security products. Increasingly, they power classification, threat detection, triage, and analyst workflows. While hundreds of public benchmarks measure general reasoning and cybersecurity, none are designed to measure whether an LLM understands email communication and email security as first-class domains.
Emailbench fills that gap. It is a compact, high-quality benchmark for email understanding, built entirely from open sources and designed to be practical for model evaluation and iteration.
Why a dedicated email benchmark?
Email has its own ecosystem: protocols, headers, authentication standards, delivery paths, and attacker behaviors distinct from other cybersecurity domains. Models that perform well on broad benchmarks can still miss important email-specific concepts. This is especially true if you care about:
- authentication and identity signals (SPF, DKIM, DMARC)
- phishing and social engineering patterns
- header and routing semantics (MTA/MUA, Received chains, envelope vs. header)
- secure handling practices and trust cues
To address these gaps, emailbench focuses on foundational concepts that repeatedly appear in real-world email security.
What is emailbench?
Emailbench is a multiple-choice question-answer (MCQA) dataset consisting of 312 questions derived from the Wikipedia “Email” page and a curated set of directly linked pages (for example, SMTP, SPF/DKIM/DMARC, MIME, phishing, spoofing, and related fundamentals).
Each example includes:
- a four-option multiple-choice question
- a single ground-truth answer
- metadata (for example, category, estimated difficulty, and source citations)
Here’s a representative example:
{
"question": "What is the proper SMTP envelope sender for a bounce message?",
"ground_truth_answer": "B",
"gold": [
1
],
"choices": [
"(A) The RFC 2822 From header of the original message",
"(B) An empty path: MAIL FROM:<>",
"(C) The postmaster address of the sending domain",
"(D) The Sender header of the original message"
],
"question_category": "factual",
"estimated_difficulty": 3,
"citations": [
"One special form of a path still exists: the empty path MAIL FROM:<>, used for many auto replies and especially all bounces."
],
"question_generating_model": "azure/gpt-5",
"document_summary": "A bounce message is an automated email notifying the sender that a previous message could not be delivered; it may arrive immediately or after retries, and is formally known as an NDR/NDN or DSN...
"wiki_title": "Bounce_message",
"wiki_url": "https://en.wikipedia.org/wiki/Bounce_message",
"index": 67
}
How we built it
The goal wasn’t trivia. It was to create questions that are:
- accurate
- clearly worded
- closed-book answerable (generalizable, not niche edge cases)
- email-security relevant
- foundational
The process was as follows:
- Scrape and curate the Wikipedia “Email” page and directly linked articles.
- Generate MCQA items using a benchmark-generation workflow.
- Semantic deduplication (embedding and clustering) to remove near-duplicates.
- Apply an LLM-as-judge pass or fail filter against the criteria above.
- Perform human review to remove ambiguous wording, leakage, and remaining duplicates.
- Run sanity check using “LLM-as-student” evaluation: run strong models on the dataset to surface low-quality questions that slipped through.
This combination (automatic generation + multiple filtering layers + human review) produced a dataset that’s small enough to run often but curated enough to be useful.
NOTE: Human review focused on removing poorly worded or confusing questions, near-duplicates, and questions that clearly referenced the source text or other external data sources (not truly “closed-book”). As with any dataset derived from public sources, there might still be inaccuracies. If you find one, let us know.
What it’s for
Emailbench is intended as a practical tool for teams building email-focused AI systems:
- Model selection: Choose models optimized for email understanding, not just general ability
- Regression testing: Detect email performance drops after training, or after prompt or tooling changes
- Domain adaptation measurement: Quantify whether continued pre- or post-training improves email understanding
- Benchmark generation workflow: demonstrate a repeatable approach for producing domain benchmarks from documentation-like sources
Experiments and results
A) Comparing closed- and open-weight models
Goal: Measure how well popular closed-weight (frontier) and open-weight models handle email-specific concepts
Method: We integrated emailbench into the Hugging Face lighteval benchmarking harness as a generative task. We then ran it against various frontier and open-weight models using a simple prompt:
The following is a multiple choice question (with possible answers) about email communication and security. Your job is to select the correct answer.
Question: {{question}}
Choices:
A. {{choice_a}}
B. {{choice_b}}
C. {{choice_c}}
D. {{choice_d}}
Respond only with the letter of the correct answer, A, B, C, or D. No other text or commentary.
Answer:
Results: Extractive match accuracy is described in the sections that follow.
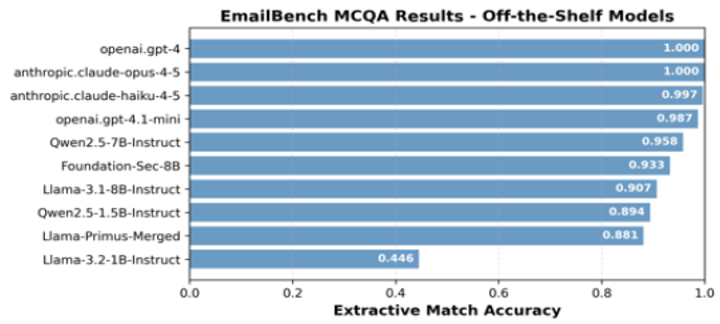
Frontier models: Large frontier models achieved 100% accuracy. This isn’t surprising, given that the source Wikipedia pages are included in their training data. Even smaller frontier models performed at 98% accuracy and above.
Open models:
- 1B - 2B Parameters: Qwen2.5-1.5B-Instruct doubled the performance of Llama-3.2-1B-Instruct, and even outperformed Llama-Primus-Merged, an 8B-parameter model fine-tuned for cybersecurity knowledge.
- 7B - 8B Parameters: Qwen2.5-7B-Instruct outperformed both Llama-3.1-8B-Instruct and cybersecurity-specific fine-tuned models. These include Foundation-Sec-8B and Llama-Primus-Merged, which were derived from the Llama-3.1-8B base model.
From this study, we can conclude that frontier models have maximum accuracy. The Qwen2.5 family of models performed best among the open-weight models of both size classes. They even outperformed models fine-tuned on general cybersecurity data.
B) Measuring the impact of continuous pre-training on a 1B parameter model
The second experiment measured how continuous pre-training (CPT) affects email understanding — both gains and regressions. We used Wikipedia source data for the benchmark because it’s highly relevant by definition. We also used a different open-source corpus related to email for the test and validation sets.
Base model: We wanted to quickly run CPT on a small model under 2B parameters. Looking at the evaluation results, the meta-llama/Llama-3.2-1B-Instruct model met that criterion and showed most room for improvement on emailbench.
Dataset: For training, we used the same subset of Wikipedia pages used to generate emailbench. This included just 17 documents, giving the model the most relevant documents for the benchmark. For the validation and test sets, we sampled trendmicro-ailab/Primus-FineWeb that had high relevance to email outside of Wikipedia. As a relevance score, we used cosine similarity with the Wikipedia corpus.
Training: We used a simple CPT setup with the Hugging Face trl library. We chose a small learning rate of 1e-5 and batch size of 8, optimizing the entropy loss of next token prediction. Validation loss was minimized after just one epoch of training. This was likely due to the very small size of the training set. To confirm, we then evaluated Perplexity on the held-out test set. The training and evaluation curves for each checkpoint are shown in the figure.
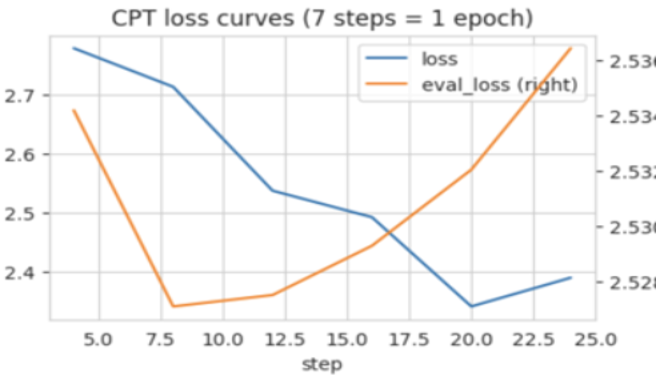
While the model overfits to the training data after just one epoch, its performance on emailbench continues to improve (see the following figure). This is an outcome of the benchmark being derived from the training set.
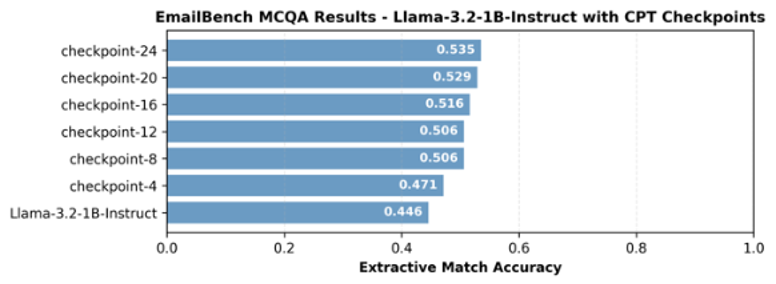
Another question we wanted to answer was how the CPT process affects model performance across other, seemingly unrelated tasks. To get a sense of this, we ran the checkpoints against a handful of public benchmarks using 200 random samples from each:
- gsm8k: grade-school math
- ifeval: instruction following
- bigbench_hard:causal_reasoning: answer a causal question about a short story.
The following figure shows the performance across these benchmarks.
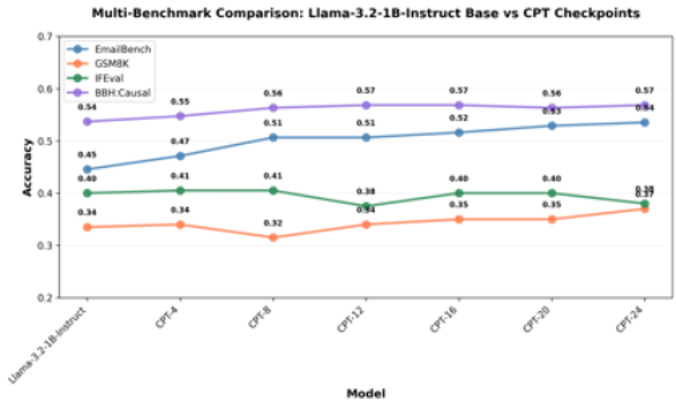
Interestingly, as emailbench performance improved with each training step, so did performance on both gsm8k and bigbench_hard:causal_judgment. This aligns with empirical evidence that fine-tuning sometimes unlocks related capabilities, even if they’re not part of the training data. In contrast, performance on obeying instructions–as measured by ifeval–showed a flat to slightly downward trend. We expect longer training cycles over more data to amplify these effects. But the results illustrate the types of improvements or regressions that coincide with any continued pre-training or fine-tuning exercise.
Open source availability and how to use
We’re releasing emailbench as an open dataset so the community can:
- evaluate email-specific understanding consistently
- compare training strategies
- build better email-security AI systems
Emailbench is available on Hugging Face. Visit: https://huggingface.co/datasets/proofpoint-ai/emailbench.
The dataset card provides an example of how to plug emailbench into the Hugging Face lighteval harness for quick experimentation.
Conclusion
Email is one of the most important–and most attacked–communication channels. If we’re going to rely on LLMs to reason about email, we must be able to measure whether they truly understand it.
Emailbench is a first step: focused, practical, and open.
We hope you find emailbench useful in your own evaluations. Happy benchmarking!
