
Engineering Insights is an ongoing blog series that gives a behind-the-scenes look into the technical challenges, lessons and advances that help our customers protect people and defend data every day. Our engineers write each post, explaining the process that led up to a Proofpoint innovation.
Organizations face constant threats from insider activities. This makes it crucial to identify when user behaviors deviate from normal patterns. Another critical use case is preventing sensitive data from leaving an organization undetected.
At Proofpoint, we have designed a sophisticated anomaly detection pipeline. Not only does it model individual user behavior profiles, but it also aggregates tenant-specific insights. This enhances its accuracy in detecting and preventing security threats.
There are unique challenges when it comes to detecting anomalous behavior in a multi-tenant system. We must preserve data isolation while also ensuring scalability. The model must also handle data sparsity as well as perform complex feature engineering to ensure that the most statistically significant user activities are considered.
We have successfully used multimodel endpoints (MME) to operate efficiently at scale. Here’s how.
User behavior profiling
To detect anomalous activities, we first compute comprehensive user behavior profiles (UBP). Each UBP captures distinct behavioral patterns for individual users across the whole tenant. We do this for every tenant completely separately from each other, adhering to strict data compliance policies.
This profile encapsulates key statistical metrics such as modified standard deviation, percentile values and other derived metrics. In this way, we effectively characterize a user's activity distribution over a period of several days.
We determined that user activities along the direction of least variance are often the most critical indicators of anomalous behavior. By prioritizing low-variance features, it’s possible to identify behavioral signals that are more meaningful, thereby improving the model's robustness to noise.
The traditional modeling approach recommends dropping low variance features as these can be less informative and prone to noise. However, for modeling activity behavior, low variance features can provide a normal behavior pattern which can be helpful when it comes to identifying peer group clusters. And slight variations must not be ignored as noise. For example, a VPN proxy for office users from a certain location may be low variance. But a change in access source IP may potentially indicate an anomaly.
Data isolation
Data security and privacy were key considerations given that it’s a multi-tenant system. We ensured strict data segregation to prevent any information leaking between tenants. Each user's profile is constructed from data that belongs to that specific user’s tenant. Further, each tenant has its own separate machine learning (ML) model. This design enforces robust data isolation.
Tenant profiles
We also computed tenant profiles that characterize overarching behavioral patterns across the customer’s environment. Tenant profiles identify key metrics such as website usage patterns, activity trends and other tenant-wide attributes. We then combined user profiles with broader tenant patterns. And then we enhanced the system’s ability to distinguish legitimate deviations from false positives.
Inference
Our inference pipeline evaluates a user’s current activity within a defined time window. Both the user behavior profile and the corresponding tenant profile are used to compute a dynamic anomaly score for the user's current activity pattern.
Activities that deviate significantly are flagged as anomalies. Anomalous events are then flagged and added to the data model along with explainability which is then finally rendered in the UI as shown in Figure 1 below.
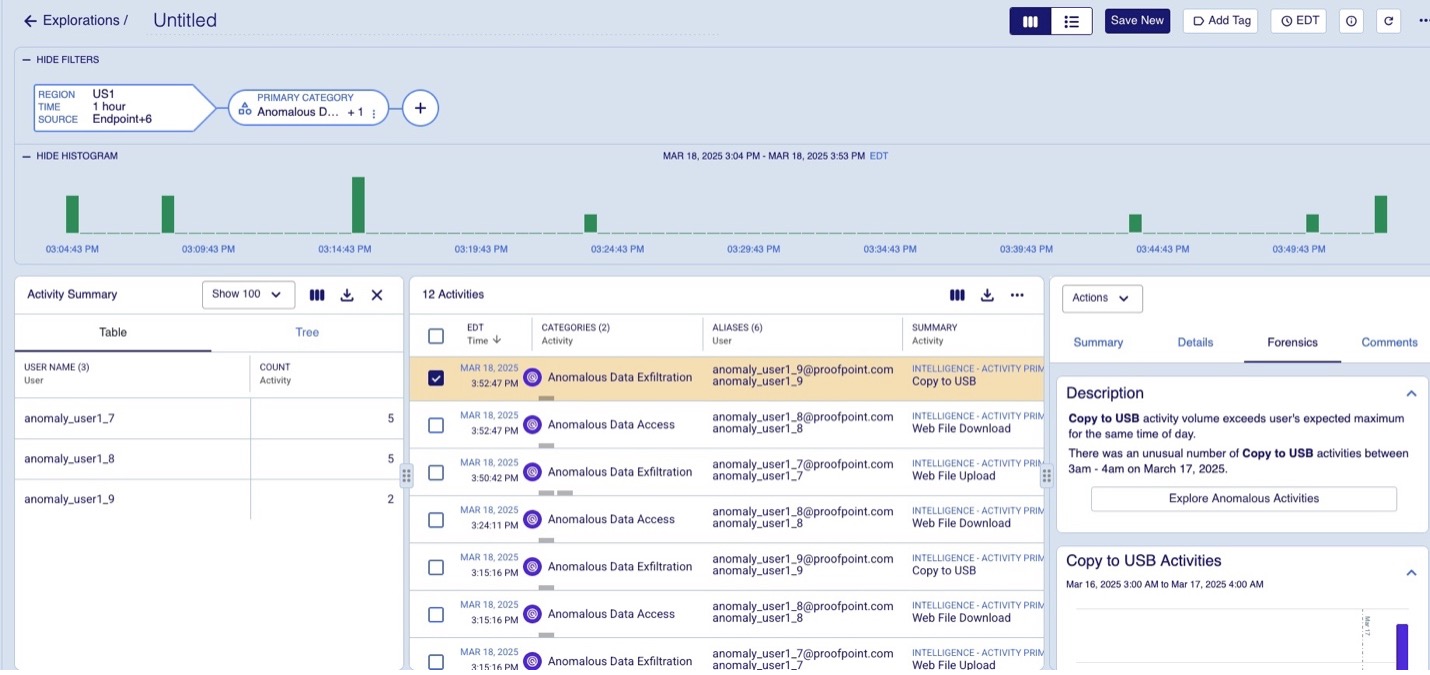
Figure 1: Flagged anomalous activities.
To scale the system efficiently we used multimodel endpoints. Our inference pipeline is shown in Figure 2.
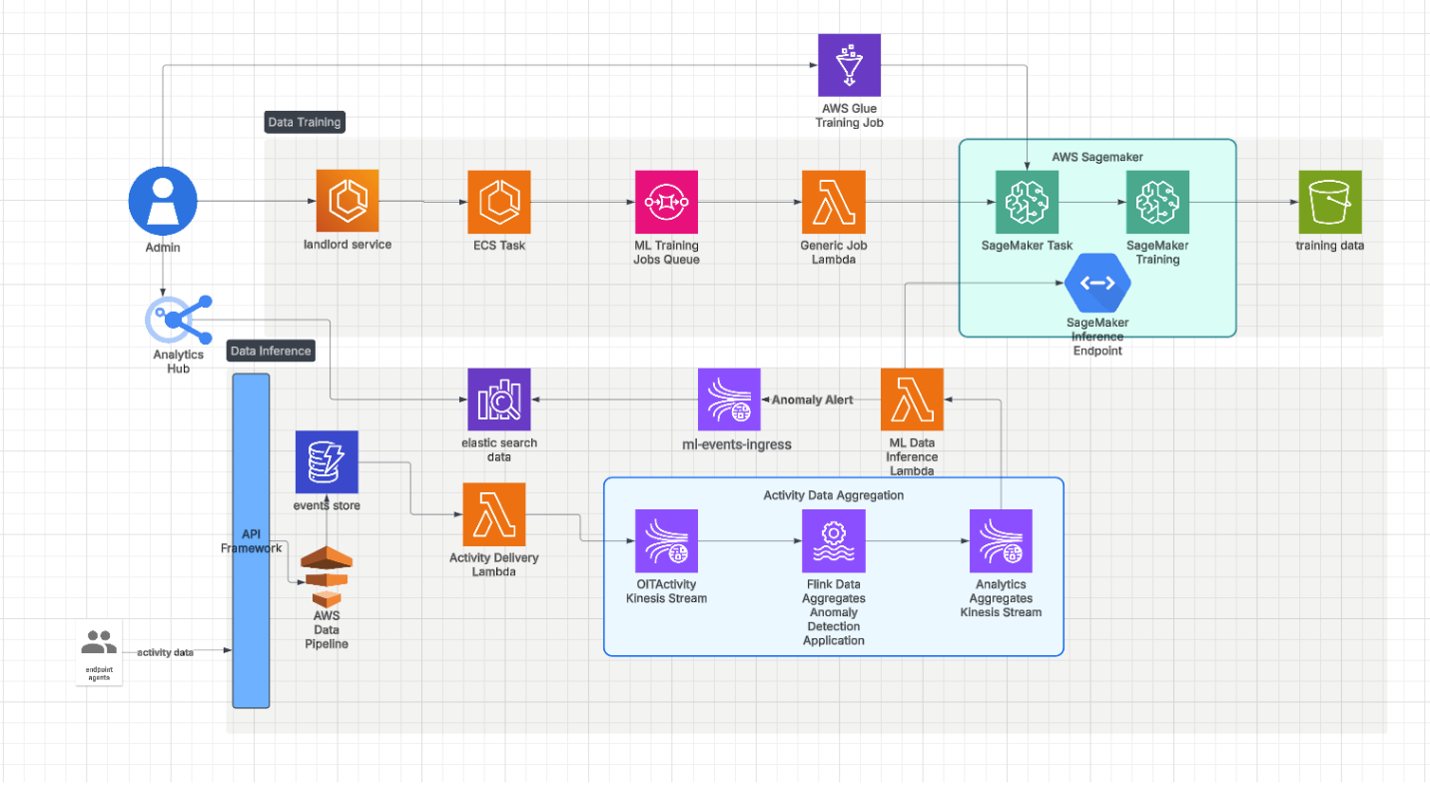
Figure 2: Pipeline architecture.
MMEs allow multiple models to be hosted on a single endpoint. This enables dynamic, on-demand model loading and unloading. It’s an approach that significantly reduces infrastructure costs because it enables resource utilization to be optimized.
It also maintained low latency for real-time inference roundtrip based on our tests. Every machine learning (ML) model is stored in blob storage and dynamically loaded when required. This enables fast and efficient model switching. MMEs allowed us to manage several models under a single endpoint, streamlining our deployment strategy. This allowed us to scale seamlessly as the number of tenants increased.
Future work
In the future, we plan to use LLMs and AI agentic workflows to augment our anomaly detection pipeline. And large language models (LLMs) could summarize activities within specified time windows, automatically extracting key insights and anomalies. This would give security analysts more actionable intelligence. It would also enable faster and more accurate decision-making. What’s more, AI agents can work from the initial anomaly findings to execute workflows, like compiling real-time file content scanning results and data lineage information to remove false positives.
Join the team
At Proofpoint, our people—and the diversity of their lived experiences and backgrounds—are the driving force behind our success. We have a passion for protecting people, data, and brands from today’s advanced threats and compliance risks.
We hire the best people in the business to:
- Build and enhance our proven security platform
- Blend innovation and speed in a constantly evolving cloud architecture
- Analyze new threats and offer deep insight through data-driven intelligence
- Collaborate with our customers to help solve their toughest cybersecurity challenges
If you’re interested in learning more about career opportunities at Proofpoint, visit the careers page.
About the authors

Ram Kulathumani is a senior manager at Proofpoint, leading ML research and development for impactful security use cases. Recently, his primary focus has been fine-tuning large transformer models, prompt engineering, evaluating LLMs and optimizing ML inference performance.

Azeem Yousaf is a senior engineer at Proofpoint specializing in developing AI-driven threat intelligence solutions. His expertise spans core algorithm development and advanced feature engineering. Outside of work, Azeem enjoys playing cricket at his local club.

Khurram Ghafoor is a senior director at Proofpoint, specializing in data platform architecture and AI/ML pipelines. With over 20 years of experience, he brings expertise in software development, scalable architecture, and the application of machine learning and AI technologies.