
Engineering Insights is an ongoing blog series that gives a behind-the-scenes look into the technical challenges, lessons and advances that help our customers protect people and defend data every day. Each post is a firsthand account by one of our engineers about the process that led up to a Proofpoint innovation.
This technical blog discusses an open-source architecture called Vitess, which provides automated data sharding on top of MySQL database instances. It was first developed by engineers at YouTube. Today, it’s a Cloud Native Computing Foundation (CNCF) project. Proofpoint is currently exploring whether Vitess is the best approach for helping us to scale our online transaction processing (OLTP) databases as more customers choose our products and our data needs grow.
The Targeted Attack Protection (TAP) Dashboard back-end team at Proofpoint processes billions of events from upstream Kafka streaming systems, transforms the data and then uses standard OLTP databases to store it. API and UI services consume the stored data using read replicas. The data is also replicated to multiple downstream data stores such as the Amazon Web Services (AWS) OpenSearch/OLAP store for search and analytics purposes.
A few years ago, we chose a storage system architecture based on limited data needs. It was a simple, manually sharded setup where data was split (sharded) using a shard key such as a customer or tenant ID, with routing logic residing in read and write services. We used a few AWS RDS databases for storage, with each master having multiple read replicas for scaling reads.
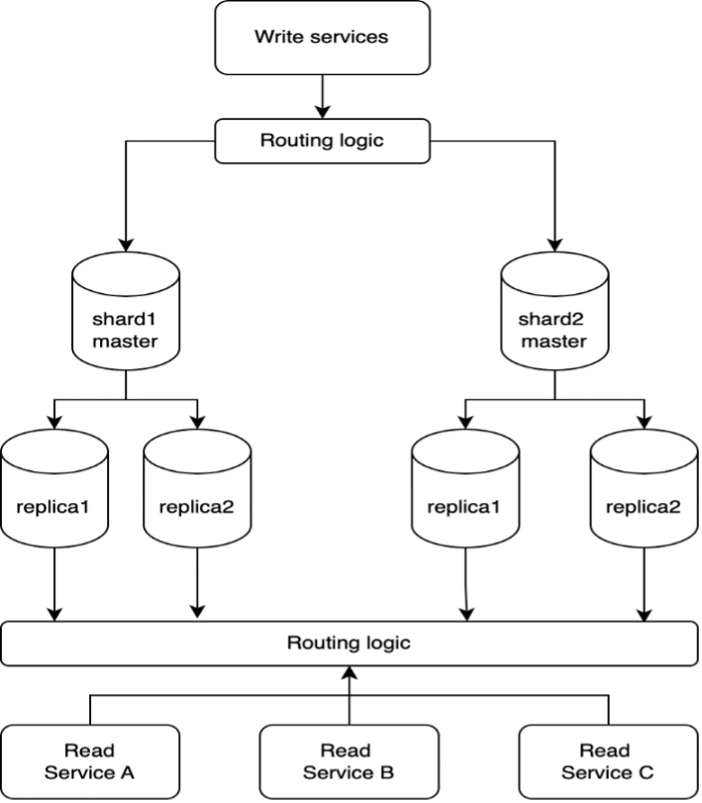
Sample manual sharding architecture.
However, we discovered that managing this architecture at scale presented many operational and maintainability challenges. For one, it can lead to outages. And the recovery time isn’t optimal because the multistep recovery process is manually intensive.
We have developed processes at Proofpoint to help us rebalance shard using techniques like shard split. The team also works continuously to improve the current system by looking at query improvement and optimization along with shard size management. Even so, it’s clear that we must explore alternatives to the current architecture to alleviate scaling challenges of 10x growth and beyond.
Garrick Dasbach, principal engineer at Proofpoint, performed an extensive investigation of various database alternatives, documenting their pros and cons. After researching available open-source databases and managed offerings, we leaned toward one project that seemed to be a suitable fit for our scaling requirements. We believed this architecture, known as Vitess, would be compatible with our existing system, providing a manageable migration path.
Vitess: A potential solution for providing long-term architecture stability
It seems the engineering team at YouTube faced similar challenges with their back end OLTP database, which was manually sharded. As YouTube experienced significant data growth, it became increasingly hard to maintain the OLTP database. The engineers developed the Vitess architecture as a way to tackle the issue. The database solution sits on top of MySQL and provides massive scalability, performance and cluster management capabilities.
Vitess was open-sourced a few years ago and has been in active development ever since. It is now a Cloud Native Computing Foundation (CNCF) project that supports cloud native deployment, meaning it can be deployed on any standard Kubernetes (K8) system. (Extensive documentation about the technology can be found here: https://vitess.io/.)
Below is a sample Vitess architecture using the AWS tech stack. Vitess can be deployed on top of AWS EKS (Elastic Kubernetes Service) with S3 as a backup store. Another important aspect of the technology is that it offers the ability to replicate data via the Debezium CDC plug-in.
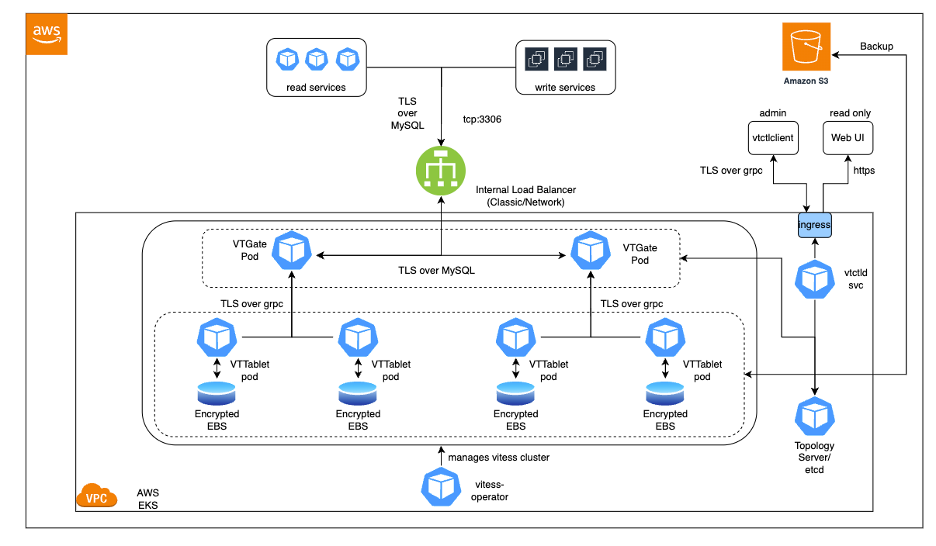
Sample Vitess architecture deployed on top of an AWS tech stack.
Proofpoint is now conducting a proof of concept (POC) with Vitess. It’s a substantial undertaking with many moving parts. But we’re confident that this software will be a worthwhile time investment for long-term architecture stability. As we make progress on this project, we will share lessons learned to help others who want to investigate this technology.
Meanwhile, if you’d like to learn more about Vitess, see the tables below. You’ll find an overview of need-to-know terminology and examples of use cases that the technology can help solve.
Key terminology
|
Terminology |
Description |
|
cell |
A cell is a cluster in Vitess that provides the lowest level of isolation. In a deployment context on AWS, a cell can be defined as an availability zone (AZ). But it can also be defined as a region in the case of a multi-region setup. The main idea here is to separate the vttables/MySQL nodes in different cells (aka AZ/regions) for increased reliability and fault tolerance. |
|
keyspace |
A keyspace is a logical database. It can comprise several physical databases in case it’s sharded. An unsharded keyspace is a single logical database. |
|
materialize |
A materialize workflow lets you define the rules of replicating data from a source table to target table. For example, when you create a reference table, you can define the materialize rule based on which data is extracted from the source table. Learn more here: https://vitess.io/docs/17.0/user-guides/migration/materialize/ |
|
reference table |
Reference tables allow Vitess to create and replicate tables from an unsharded keyspace to a sharded keyspace. It makes the join table queries more efficient as cross-shard joins are less performant compared to joining within a shard. Get more information here: https://vitess.io/docs/17.0/user-guides/vschema-guide/advanced-vschema/#reference-tables |
|
shard |
Shard in a Vitess context is a way to divide a keyspace into multiple logical databases, each with master/replica/read-only setup.
Shard is defined in terms of hexadecimal range. For example, two shard systems would divide the data into -80 (anything before 0x80) and 80- (anything after 0x80) key ranges. |
|
vindex |
vindex is a way to define mappings between keyspace IDs (shard keys) and columns of tables in sharded keyspaces. Get more details here: https://vitess.io/docs/17.0/reference/features/vindexes/ |
|
vitess sequence |
A vitess sequence is an approach to generating auto increment sequences for sharded keyspace tables instead of using the MySQL auto_increment feature. Learn more here: https://vitess.io/docs/17.0/reference/features/vitess-sequences/ |
|
vreplication |
vreplication is a low-level Vitess concept to provide a replication feature. Some higher-level features such as MoveTable and Reshardin use the vreplication feature. Get more information here: https://vitess.io/docs/17.0/reference/vreplication/vreplication/ |
|
vschema |
vschema provides a unified schema view of all keyspaces on a Vitess cluster. Learn more here: https://vitess.io/docs/17.0/reference/features/vschema/ |
|
vstream |
vstream is a unified change notification via VTGate (like binlog events for a MySQL database), which the client can use to get all event updates (insert, delete, update) for a Vitess cluster (including all keyspaces). Find out more here: https://vitess.io/docs/17.0/concepts/vstream/ |
|
vtctlclient |
vtctlclient is a client version that talks to the Vitess vtctld server on a Vitess cluster. Find out more here: https://vitess.io/docs/17.0/concepts/vtctl/ |
|
vtgate |
vtgate is a top-level component that is the first point of contact for an external client connection. It implements a MySQL-based protocol and offers an illusion to the external client as if it’s talking to a single MySQL database. |
|
vttablet |
A vttablet is a component that manages a single MySQL instance. There’s always a 1:1 relation between a vttablet and MySQL instance. Therefore, it resides in the same location where it’s corresponding MySQL server is hosted/installed. Vitess supports unmanaged tablets where the vttablet component doesn’t actively manage the life cycle of the MySQL instance (e.g., AWS RDS). |
Use cases Vitess can help to solve
|
Use case |
Details |
|
Automated sharding |
The sharding logic is solid and has been designed in such a way that you can go from 1x to 10x in a short period without any interruption to system performance. |
|
Massive scalability |
An architecture like Vitess provides an automated solution for adding new database storage and splitting data; this, in turn, enables massive scaling of a database. |
|
Materialize |
With a solution like Vitess, you can create materialization of multiple tables and columns into a new table for performing aggregation tasks. Vitess uses vreplication, which is a way to read binlog data from an individual shard database to get the latest updates (create, delete, update) for any table. |
|
Online schema migration |
Vitess uses tools like gh-ost and Percona’s online schema migration tool, providing the ability to perform table migration without any downtime. |
|
Query caching, connection pooling |
Vitess components provide query caching and connection pooling to improve overall performance. |
|
Resharding |
The resharding operation is straightforward with vtctlclient. Splitting the database isn’t a challenging and manual process; it involves minimal application downtime. |
|
Table replication from one database (keyspace) to another database |
The Vitess reference table feature offers a way to create a single source of truth (one separate database) and replicate it across other databases (keyspaces). |
About the author
Debraj Maity is a staff software engineer at Proofpoint. He is a hands-on technical lead with extensive experience building complex software products and solutions. He holds a master’s degree in computer science from the University of Texas at Dallas.
