
As cyber threats continue to evolve at an unprecedented pace, many organizations are turning to machine learning (ML) and artificial intelligence (AI) in their cybersecurity in hopes of keeping up.
While these advanced technologies hold immense promise, they’re also more complex and far less efficient than traditional threat detection approaches. The tradeoff isn’t always worth it.
And not all AI and ML processes are created equal. The models used, the size and quality of the data sets they’re trained on—and whether an advanced computational process is suitable for the problem at hand—are all critical factors to consider when deciding how to fit both ML and AI into your cybersecurity strategy.
In this blog post, we explore and explain the vital ML and AI questions you should ask your cybersecurity vendor about these technologies. We will also demystify their role in safeguarding your people, data, and environment.
Note: Though often conflated, AL and ML are related but distinct concepts. For simplicity, we’re using AI when discussing the broader technology category and ML to discuss narrower learning models used in AI.
AI Question 1: Why is AI suitable for this security problem?
You’ve probably heard the old saying that when your only tool is a hammer, every problem looks like a nail. While there is some rightly generated enthusiasm around AI in cybersecurity, it may not be the optimal approach to every task.
On one hand, the technologies can help analyze large amounts of data and find anomalies, trends, and behaviors that indicate potential attacks. And the technologies can automate response and mitigation of security incidents.
But depending on the size and complexity of the learning model, they can also be computationally intensive (read: expensive) to maintain. And worse, execution time can be much longer than less complex approaches such as rules and signatures.
On the other hand, rules and signatures are static, so they don’t automatically evolve to detect new threats. But they’re also fast, easy on computing resources, and highly effective for certain aspects of threat detection. Other signals, such as email sender reputation and IP addresses, can also be as effective as AI for many detections—and in most cases are faster and much more cost-effective.
Getting AI right starts with understanding what cybersecurity tasks they’re best suited to and applying them to the right problems. In the same vein, how the technology is applied matters.
In cybersecurity, every second counts. Making decisions in real-time and blocking malicious content before it can be delivered is today’s key challenge. If the processing time of the vendor’s AI means the technology is relegated solely to post-delivery inspection and remediation, that’s a major drawback.
AI Question 2: Where do you get your training data?
The performance of ML models hinges on the source and quality of their data. That’s because AI models learn from examples and patterns, not rules. And that requires a large amount of data. The more data, and the higher the quality of that data, the better the model can learn and generalize to new conditions.
Like any ML model, those used in cybersecurity need a wide-ranging, diverse data set that accurately reflects the real world. Or more precisely, the data used to train your vendor’s AI model should reflect your world—the threats targeting your organization and users.
Finding data for general-purpose AI applications is easy. It’s all over the internet. But threat data—especially data well-suited for the type of ML model the vendor intends to use— is scarcer. Gaining malware samples is a lot harder than acquiring data used in applications such as image and natural language processing.
First, not much attack data is publicly available. Most security vendors hold on tightly to the threat data they collect, and for good reason. Beyond the obvious competitive advantages it offers, threat data is sensitive and comes with a bevy of privacy concerns. As a result, few cybersecurity vendors have a dataset large enough to train (and re-train) models accurately.
It’s also crucial that the training data is accurately labeled. This is a task best performed by expert threat analysts working with data scientists, rather than data scientists alone. The vendor’s breadth of capability matters. (This is an area where new market entrants often struggle.)
AI Question 3: Do you supplement the AI with blocklists/safelists, signatures or other mechanisms?
A detection stack that relies too heavily on AI could be a problem. For many threat scenarios, the technology is slower, less efficient, less effective, and less reliable than other defensive layers.
That’s why rules, signatures, and other signals can be a powerful complement to AI in cybersecurity. Sometimes the best approach is to use signatures and rules to quickly detect known and common cyber threats and reserve AI for unknown and evolving threats.
One approach is to use a sophisticated ML model to surface novel attacks to a team of threat researchers, who then train ML models in the production detection stack. This “human-in-the-loop” model allows the AI to be far more sensitive than would be possible in a production system (that is, without drowning in a sea of false positives). A human-aided approach leverages researchers’ expertise without giving up the speed and self-learning benefits of AI in the production environment.
Rules and signatures can also complement AI by providing context and domain knowledge that the ML model lacks or struggles to learn. For example, rules and signatures can encode the policies, regulations, standards, and best practices that apply to a particular business domain. They can also capture the specific traits, behaviors, and patterns of threats that are relevant to your organization, industry, or geography.
AI Question 4: How often do you update your ML models to adapt?
Cyberattacks are constantly evolving, limited only by the determination and creativity of the people behind them. ML models need to adapt, so regularly updating them is critical.
In data science circles, this issue is known as model drift. It occurs when the model no longer reflects real-world data, degrading performance over time.
For example, cyber attackers may use new techniques or tools to evade detection. Or they may change their behavior or tactics to exploit new vulnerabilities. ML models need to be updated with new data and feedback to account for these changes.
Beyond model drift, some attacks involve deliberate attempts to fool or manipulate ML models. For example, data poisoning (injecting malicious data into the training dataset) can cause the model to make incorrect predictions, miss detections or create a flood of false positives. Or the attacker craft inputs that are misclassified by the model, such as adding noise to malware samples, to evade detection.
That’s why ML models used in production detection stacks need to be updated regularly—ideally multiple times per day.
AI Question 5: What metrics are you using to quantify performance?
To gauge the effectiveness and reliability of ML models, most experts focus on two key metrics: accuracy and precision. Here’s how they’re defined:
- Accuracy. This is the proportion of correct predictions made by the ML model out of the total number of predictions. Accuracy measures how well the model can correctly tell cyber threats apart from benign activities. A high accuracy means the model has a low error rate and can reliably detect cyberattacks.
- Precision. This is the proportion of true positives (correctly identified cyber threats) out of the total number of positive predictions (all identified cyber threats). Precision measures how well the model can avoid false positives. A high precision indicates that the model has a high specificity and can minimize the impact of false alarms on security operations.
These metrics are often expressed in graphic terms using receiver operating characteristic (ROC), which shows the performance of the model for cyber threat detection at different thresholds. The so-called “area under the curve” (AUC) quantifies the performance of the ROC curve.
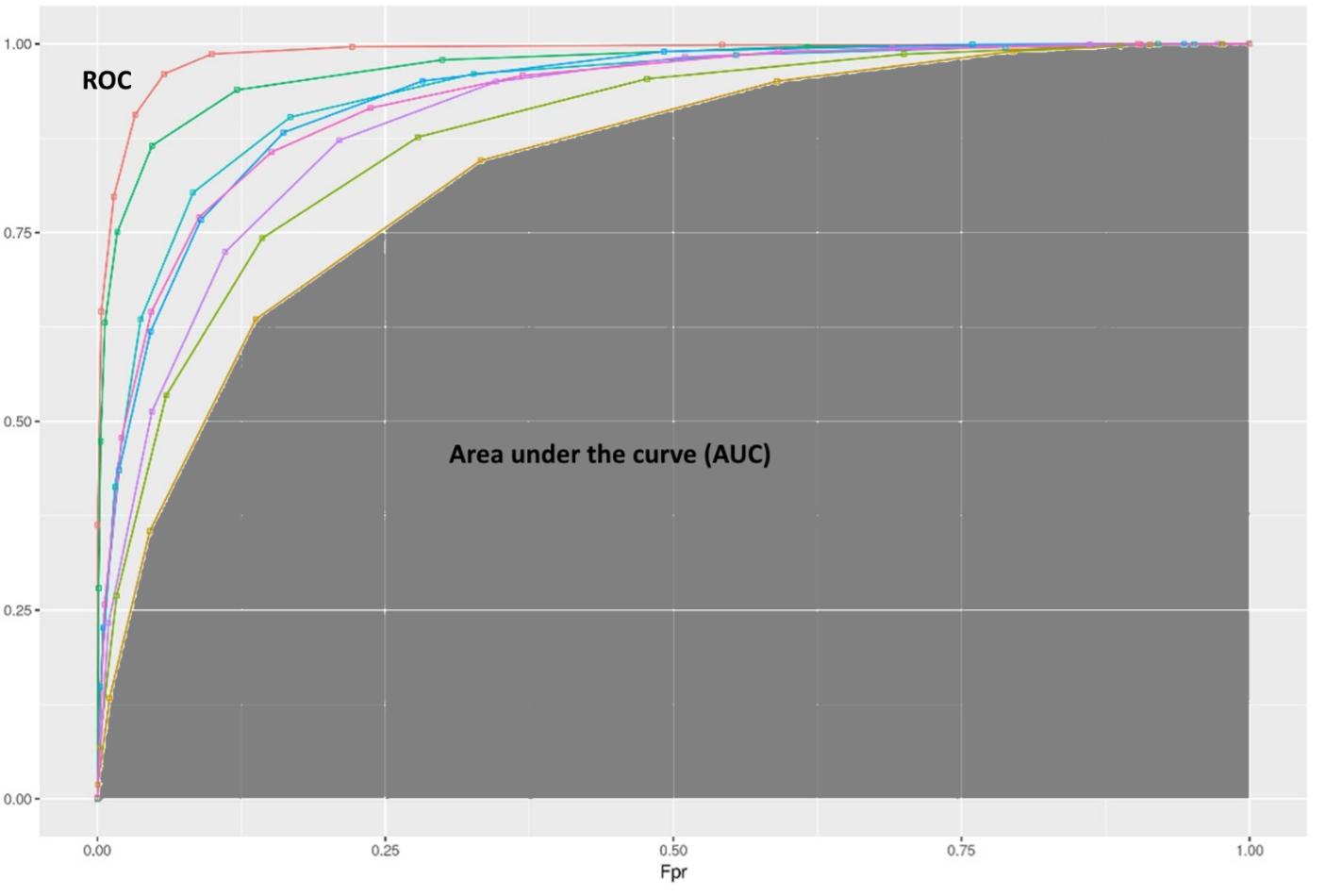
Typical ROC curve. (Credit: Sumit Asthana, used and modified under the Creative Commons Attribution-Share Alike 4.0 International license.)
Some experts also consider the efficacy and efficiency of the ML model’s critical metrics. Here’s how they’re defined:
- Efficacy. In cybersecurity, accurately detecting threats is only part of the challenge. Detecting them quickly is just as critical. That’s why the speed of the ML model is an important factor to consider—and a reminder why AI may not always be the best approach to start with.
- Efficiency. Cost is always a factor to consider in AI cybersecurity tools. The rule applies not just to your cost as a buyer but to the vendor’s operational costs. If the vendor uses AI in inefficient ways, they may have an unsustainable business model. If you’re looking for a long-term security partner, the vendor needs an AI approach that can survive and thrive at scale without a constant stream of outside funding.
Additional tips:
Your vendor should have trained and tested its ML models with datasets that are large and diverse enough to measure expected performance for real-world threats targeting your environment. They should also test the models against other analytical techniques to ensure that the AI is more than a marketing gimmick.
To accurately gauge the model’s performance, it’s also important to use separate data for training and testing. The vendor’s testing samples should be meaningfully different from its training data—the whole point of AI is the ability to detect patterns in new signals that the model has not yet encountered.
Assessments should also include seeing how the model reacts to corrupt and data poisoning attempts to surface potential vulnerabilities or limitations in the ML model.
AI Question 6: Has this been validated by a reputable third party?
It’s easy to get lost in a morass of hype and untested claims. Even the most reliable cybersecurity vendors may have aggressive or misleading marketing that clouds good buying decisions. Their ML models may have flaws or limitations that they are not aware of or do not disclose. And sometimes, the sales rep may simply not fully understand AI technology.
That’s why third-party validation is critical. An unbiased assessment can help you compare and choose the best solutions for your unique needs and environment. With third-party validation, you can identify and mitigate these risks and ensure that the vendor’s approach to AI is effective, secure, and compliant.
And remember that validation is not a one-and-done event. Cyber threats are always evolving, so ML models, products, and services need constant improvement. Make sure that any third-party assessment of the vendor is recent and be sure to look at performance over time.
How Proofpoint uses AI in cybersecurity
From the beginning, Proofpoint has used AI to give you complete and constantly evolving protection against a wide range of external threats. Our NexusAI engine includes trillions of datapoints to continuously protect your people and your organization against attacks—before they reach users’ inbox.
Whether you're evaluating a potential vendor for the first time or considering new tools and platforms, you should know how AI and ML fit into the equation. To learn how Proofpoint uses ML and AI in cybersecurity, visit https://www.proofpoint.com/us/solutions/nexusai.